继 Meta 昨天发布最强开源大模型 Llama 3.1 后,法国 AI 初创公司 Mistral AI 也加入了竞争,今天发布了全新的旗舰开源模型 Mistral Large 2。
该模型拥有 1230 亿个参数,可在单个 H100 节点上以高吞吐量运行,在代码生成、数学、推理等方面与 OpenAI 和 Meta 的最新尖端模型不相上下,并提供更强大的多语言支持和高级函数调用功能。
Mistral 公司表示,训练的重点之一是尽量减少模型的幻觉问题。该公司称,Large 2 接受的训练让它的反应更具辨别力,当它不知道某些事情时,它会承认自己不知道,而不是编造一些看似合理的事情。
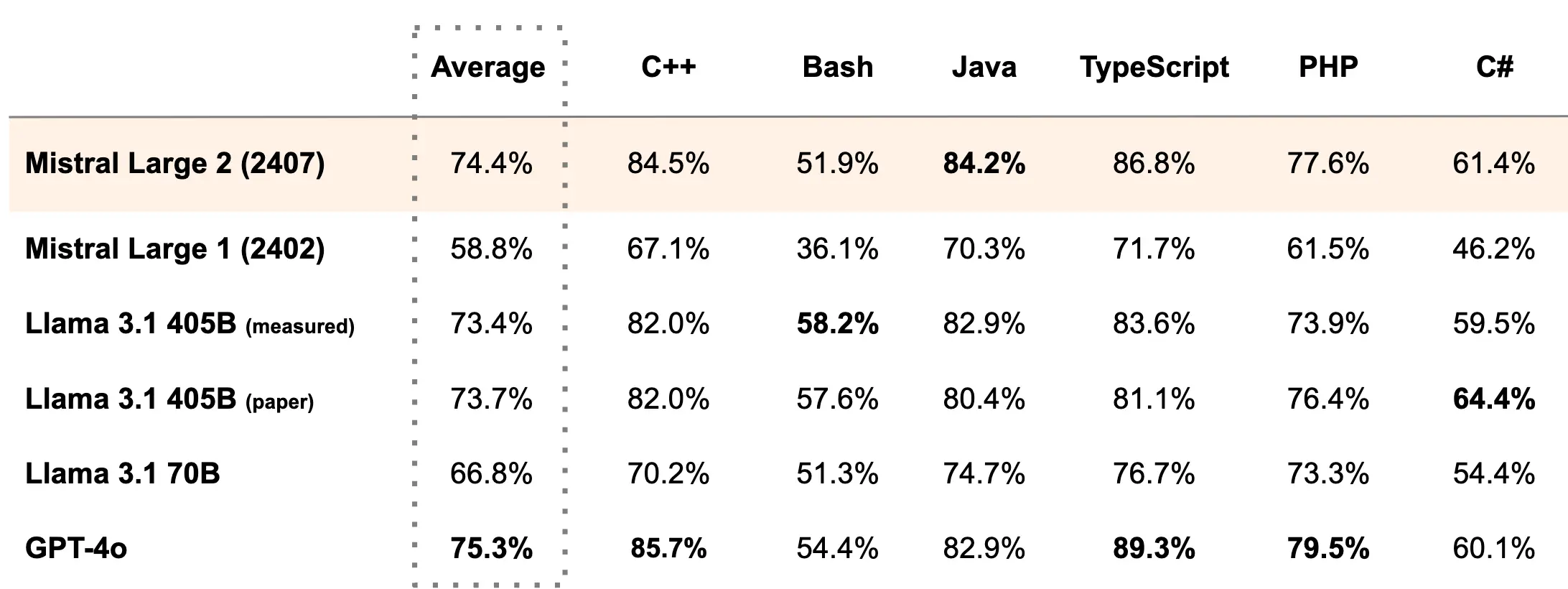
它支持法语、德语、西班牙语、意大利语、葡萄牙语、阿拉伯语、印地语、俄语、汉语、日语和韩语。在编码方面,它支持 80 多种编码语言,包括 Python、Java、C、C++、JavaScript 和 Bash。
Mistral Large 2 拥有 128k 的上下文窗口,支持包括中文在内的数十种语言以及 80 多种编码语言。该模型在 MMLU 上的准确度达到了 84.0%,并在代码生成、推理和多语言支持方面有非常明显的改进。
Mistral Large 2 虽然是开放的,但只限于研究和非商业用途。它提供了开放的权重,允许第三方根据自己的需求对模型进行微调。这一协议是对用户使用条件的一个重要限制。对于需要自行部署 Mistral Large 2 的商业用途,必须提前获取 Mistral AI 商业许可证。