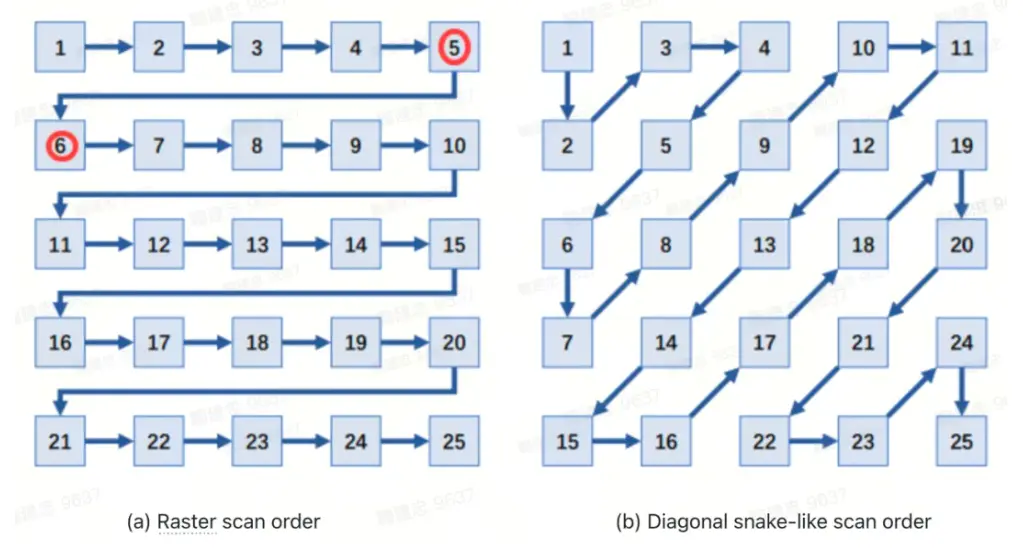
小米大模型团队宣布,其最新提出了一种新的生成方法,即具有方向感知的对角蛇形(diagonal snake-likeorder)自回归图像生成方式(DAR)。目前,相关的论文、训练代码、模型权重已经开源。
根据介绍,它不是一行一行地画,而是沿着图像的对角线、像蛇一样灵活地生成每个像素。这样的方式比传统方法更自然,也更接近人类绘画时的直觉。
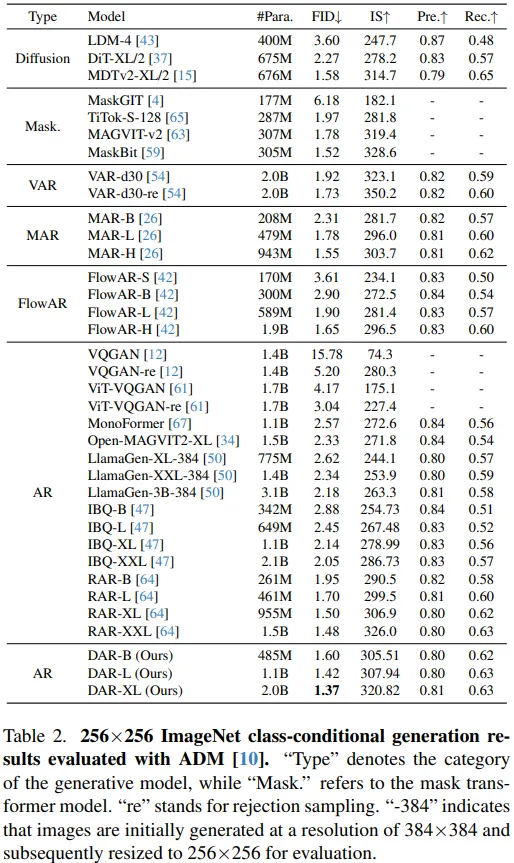
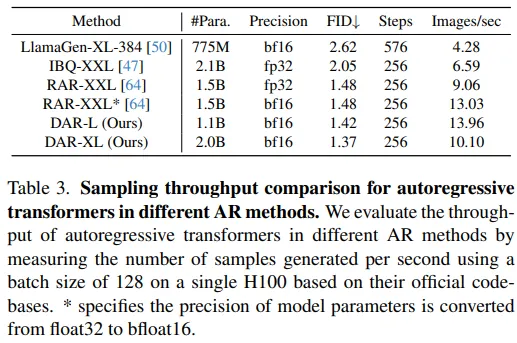
我们提出了一种具有方向感知的对角蛇形扫描自回归图像生成框架(DAR),有效地确保相邻索引的 token 在空间上紧密相邻。此外,方向感知模块显著增强了模型在处理频繁变化的生成方向上的表现。我们开发了一系列不同规模的模型,参数量从485M到2.0B不等。在实验中,我们的DAR模型在256×256的ImageNet基准测试中取得了突破性的FID分数(1.37),超越了此前所有自回归方法。
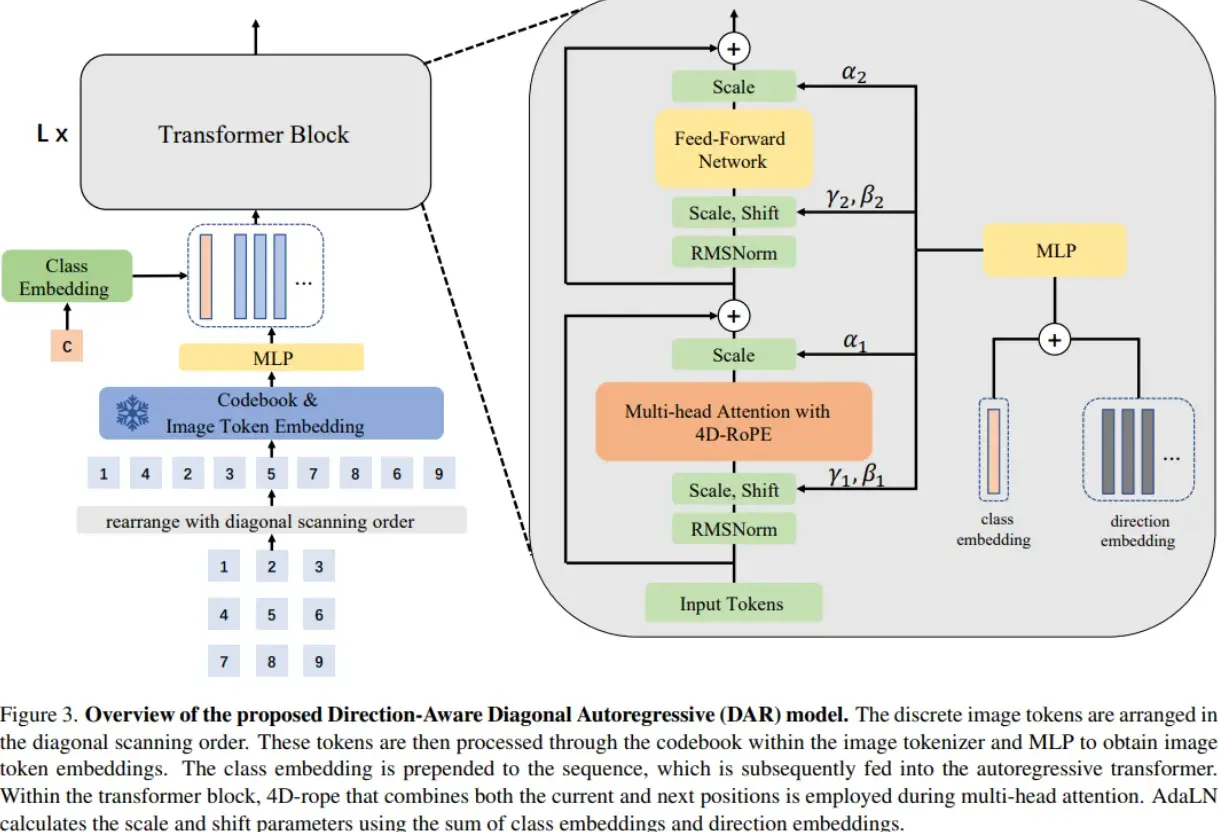
整个模型是decoder-only的结构,保持了和LLM兼容的next token prediction的训练和推理方法,decoder的网络结构跟LlamaGen一致。小米大模型团队选择IBQ工作中的image tokenizer的codebook作为图像token embedding。并创新地提出了4D-RoPE以及Direction Embedding来控制图像的生成方式。
实验结果:
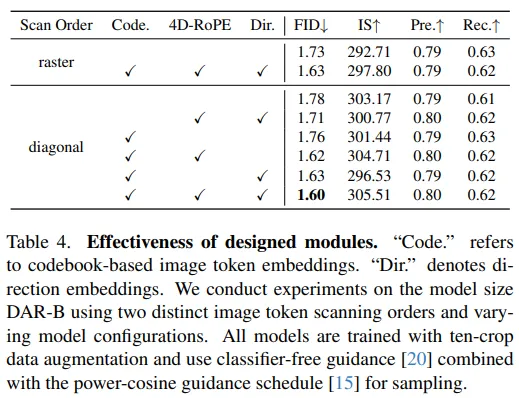
小米大模型团队方面表示,接下来将进一步支持更灵活的多种分辨率图像生成。鉴于本方法与LLM的训练和推理方式高度兼容,还将持续探索更加统一的多模态理解与生成技术方案。