红杉中国宣布推出一款全新的AI基准测试工具xbench,并发布论文《xbench: Tracking Agents Productivity,Scaling with Profession-Aligned Real-World Evaluations》。
“在评估和推动AI系统提升能力上限与技术边界的同时,xbench会重点量化AI系统在真实场景的效用价值,并采用长青评估的机制,去捕捉Agent产品的关键突破。”
根据介绍,xbench采用双轨评估体系,构建多维度测评数据集,旨在同时追踪模型的理论能力上限与Agent的实际落地价值。该体系创新性地将评测任务分为两条互补的主线:
- 评估AI系统的能力上限与技术边界;
- 量化AI系统在真实场景的效用价值(Utility Value)。
其中,后者需要动态对齐现实世界的应用需求,基于实际工作流程和具体社会角色,为各垂直领域构建具有明确业务价值的测评标准。
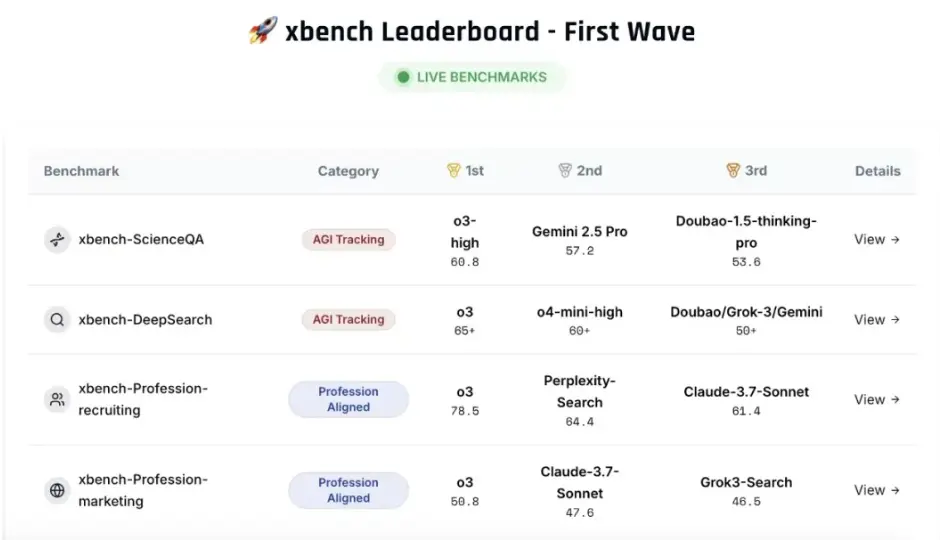
首期发布包含两个核心评估集:科学问题解答测评集(xbench-ScienceQA)与中文互联网深度搜索测评集(xbench-DeepSearch),并对该领域主要产品进行了综合排名。
同期提出了垂直领域智能体的评测方法论,并构建了面向招聘(Recruitment)和营销(Marketing)领域的垂类Agent评测框架。评测结果和方法论可通过 xbench.org 网站实时查看。
论文地址:https://xbench.org/files/xbench_profession_v2.4.pdf