中国科学院自动化研究所与中国科学院脑科学与智能技术卓越创新中心的联合团队在《自然·机器智能》(Nature Machine Intelligence)发表相关研究,首次证实多模态大语言模型能够自发形成与人类高度相似的物体概念表征系统,为人工智能认知科学提供了新路径,也为构建类人认知结构的人工智能系统提供了理论框架。
研究采用认知心理学经典的“三选一异类识别任务”(triplet odd-one-out),要求大模型与人类从物体概念三元组(来自1854种日常概念的任意组合)中选出最不相似的选项。通过分析470万次行为判断数据,团队首次构建了AI大模型的“概念地图”。
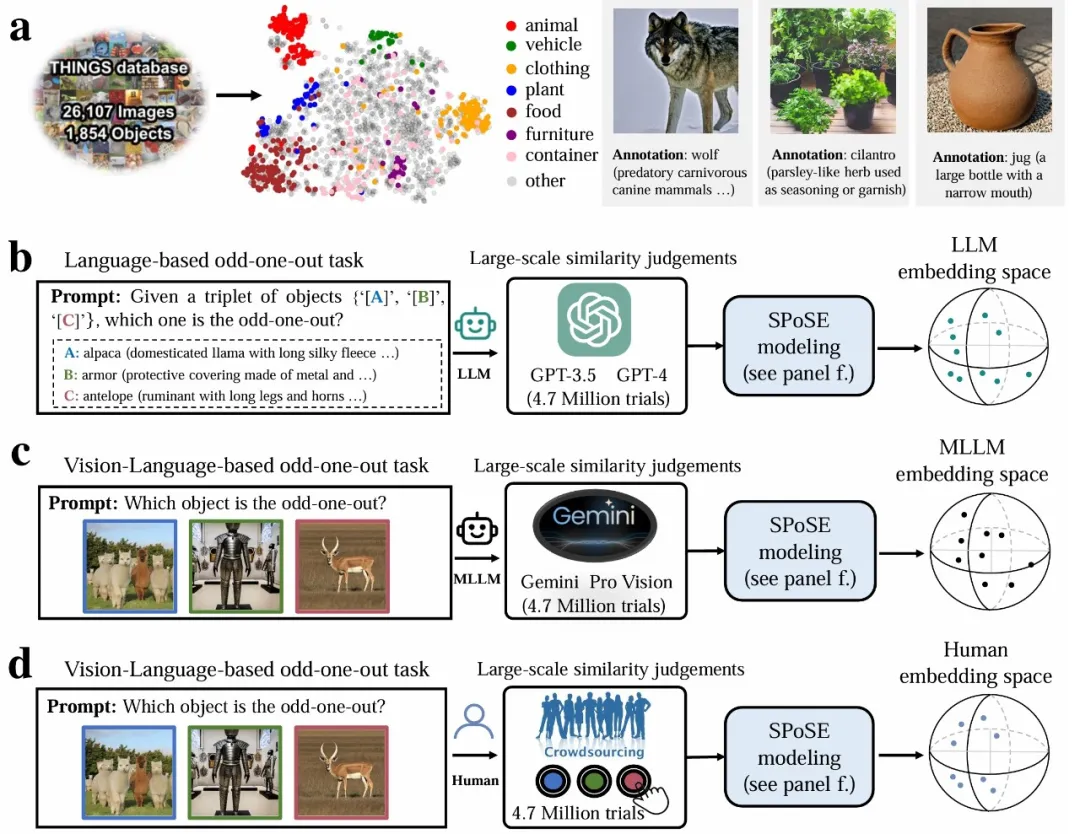
实验范式示意图。a,物体概念集及带有语言描述的图像示例。b-d,分别针对 LLM、MLLM 和人类的行为实验范式和概念嵌入空间。
研究人员从海量大模型行为数据中提取出66个“心智维度”,并为这些维度赋予了语义标签。研究发现,这些维度是高度可解释的,且与大脑类别选择区域(如处理面孔的FFA、处理场景的PPA、处理躯体的EBA)的神经活动模式显著相关。
研究还对比了多个模型在行为选择模式上与人类的一致性(Human consistency)。结果显示,多模态大模型(如 Gemini_Pro_Vision、Qwen2_VL)在一致性方面表现更优。
此外,研究还揭示了人类在做决策时更倾向于结合视觉特征和语义信息进行判断,而大模型则倾向于依赖语义标签和抽象概念。本研究表明大语言模型并非“随机鹦鹉”,其内部存在着类似人类对现实世界概念的理解。
- 全文链接:https://www.nature.com/articles/s42256-025-01049-z
- 代码:https://github.com/ChangdeDu/LLMs_core_dimensions
- 数据集:https://osf.io/qn5uv/