Meta发布了最新的开源世界模型V-JEPA 2,称其在物理世界中实现了最先进的视觉理解和预测,从而提高了AI agents的物理推理能力。

开源地址:https://github.com/facebookresearch/vjepa2
官网地址:https://ai.meta.com/vjepa/
论文地址:https://ai.meta.com/research/publications/v-jepa-2-self-supervised-video-models-enable-understanding-prediction-and-planning/
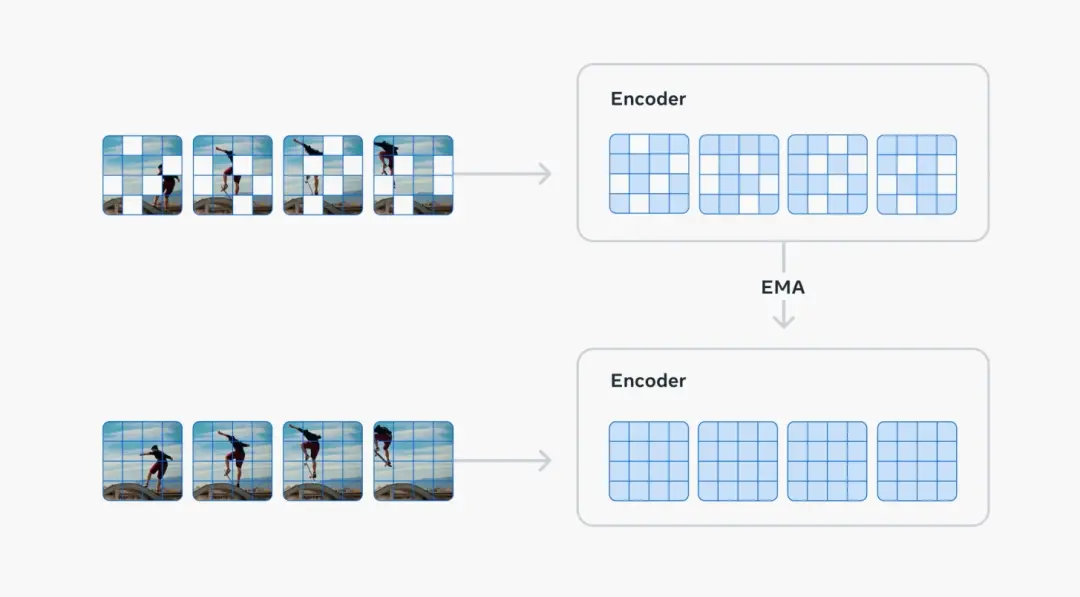
V-JEPA 2是一种联合嵌入预测架构(Joint Embedding Predictive Architecture)模型,这也是“JEPA”的名称由来。
模型包括两个主要组成部分:
- 一个编码器,负责接收原始视频,并输出包含对于观察世界状态语义上有用的内容的嵌入(embeddings)。
- 一个预测器,负责接收视频嵌入和关于要预测的额外内容,并输出预测的嵌入。
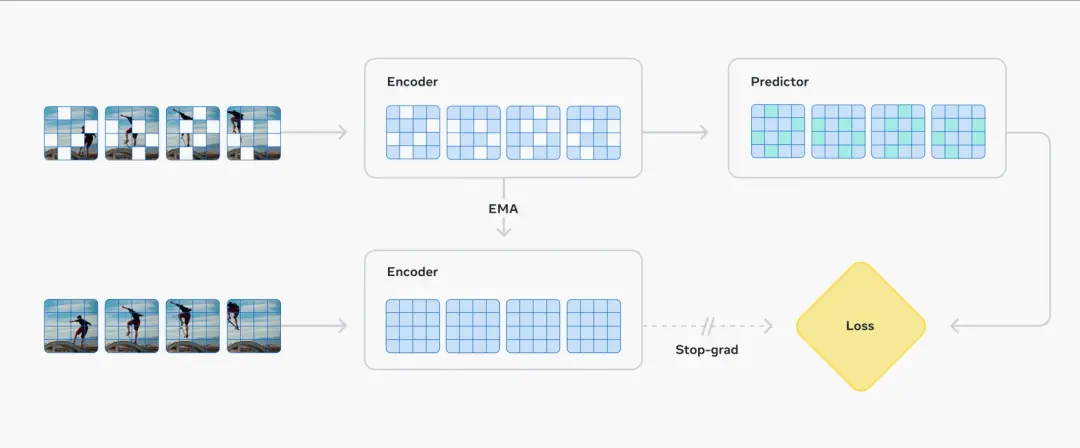
V-JEPA 2跟传统预测像素的生成式模型有很大性能差异,根据Meta测试数据,V-JEPA 2执行任务时每个步骤的规划用时缩短至Cosmos模型的三十分之一,不仅用时短,V-JEPA 2的成功率还更高。
V-JEPA 2的能力对现实世界agents理解复杂运动和时间动态(temporal dynamics),以及根据上下文线索预测动作都非常关键。基于这种预测能力,世界模型对于规划给定目标的动作顺序非常有用,比如从一个杯子在桌子上的状态到杯子在桌子边上的状态,中间要经历怎样的动作。
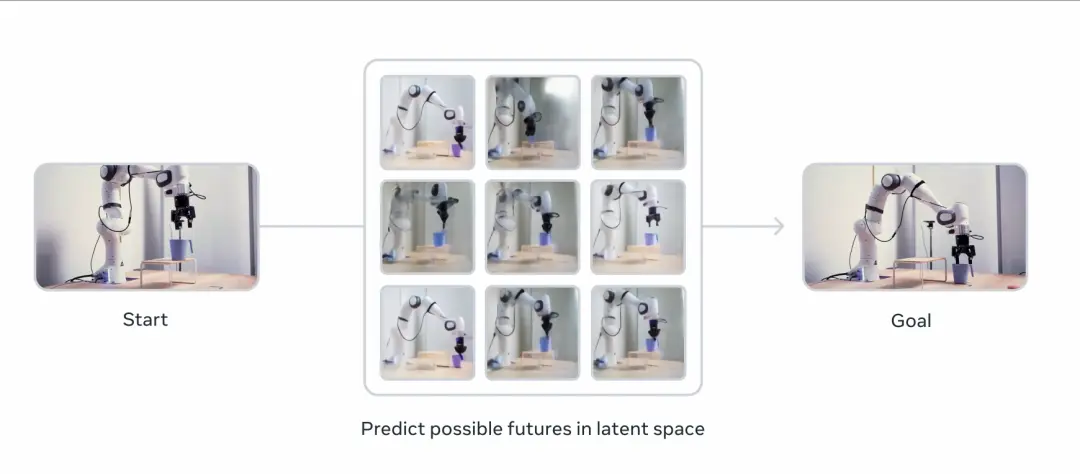
据介绍,V-JEPA 2的核心架构是一个自监督学习框架,通过互联网规模的视频数据来训练模型,使其能够学习到视频中的动态和静态信息。预训练阶段使用了超过100万小时的视频和100万张图像,这些数据涵盖了各种动作和场景。预训练的目标是让模型能够通过观察学习到世界的背景知识,而无需依赖于大量的标注数据。
值得一提的是,图灵奖获得者、Meta首席科学家杨立昆(Yann LeCun)参与了该模型的开发,这在Meta开源的众多大模型中很罕见。他在官方视频中提到,在世界模型的帮助下,AI不再需要数百万次的训练才能掌握一项新的能力,世界模型直接告诉了AI世界是怎样运行的,这可以极大提升效率。