蚂蚁集团 inclusionAI 团队发布了全面升级版的全模态模型 Ming-Lite-Omni v1.5,基于 Ling-lite-1.5 构建,总参数量为 203 亿(其中 MoE 部分活跃参数为 30 亿),在图像-文本理解、文档理解、视频理解、语音理解与合成、图像生成与编辑等全模态能力上显著提升。
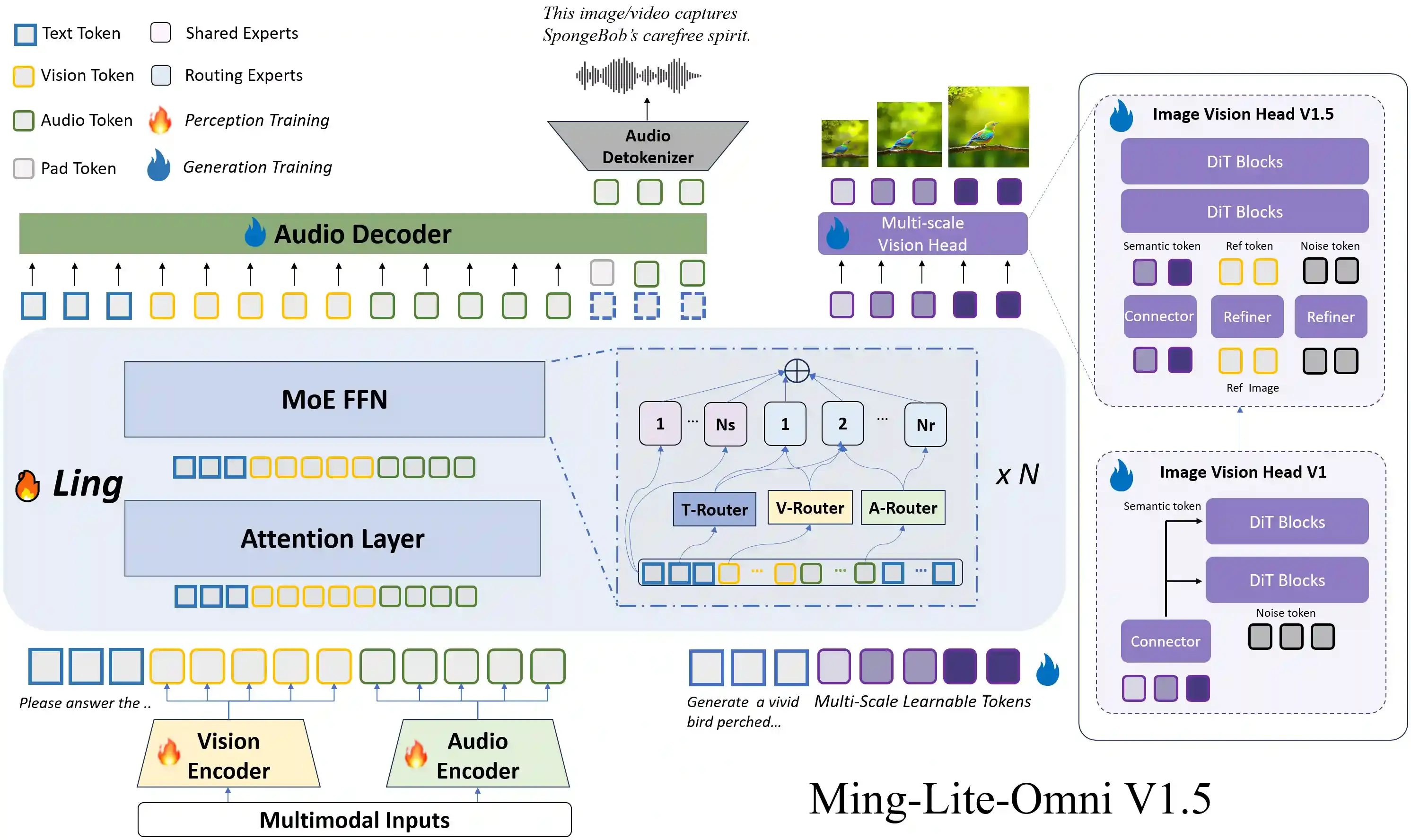
Ming-lite-omni v1.5 模型架构如下,主题参考了 Ming-lite-omni v1 版本的结构,区别在于为了增强图像编辑人物和场景一致性,升级 Vision head 支持参考图特征输入。
关键优化
- 增强视频理解:通过 MRoPE 3D 时空编码 和针对长视频的 课程学习策略,显著提升对复杂视觉序列的理解能力 。
- 优化多模态生成:采用双分支图像生成(ID 与场景一致性损失)和新的音频解码器及 BPE 编码,提升生成一致性与感知控制,实现高质量实时语音合成。
- 数据全面升级:新增结构化文本数据、高质量产品信息及包括方言(如普通话、粤语、四川话等)在内的精细化视觉与语音感知数据。
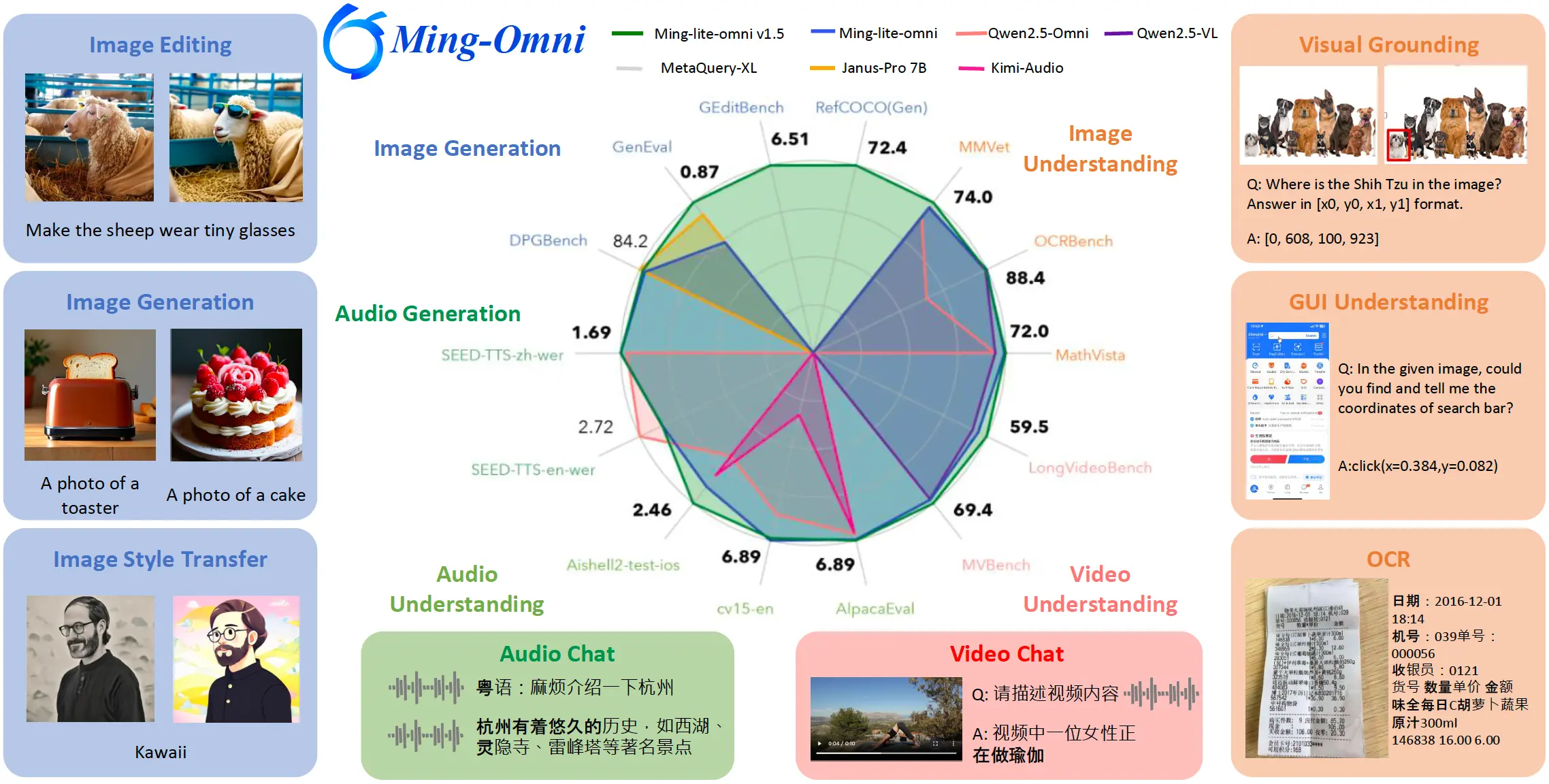
性能表现
- 在 MMVet、MathVista、OCRBench 等数据集上表现突出,文档理解任务(如 ChartQA、OCRBench)取得 10B 以下参数模型中的 SOTA 成绩。
- 视频理解、语音理解与生成(支持多种方言)及图像生成(保持人物 ID 一致性编辑)均处于行业领先地位。
该模型已在 Hugging Face 和 ModelScope 上开放下载,并提供详细安装指南、代码示例和 Gradio 演示。
Hugging Face: https://huggingface.co/inclusionAI/Ming-Lite-Omni-1.5
ModelScope: https://www.modelscope.cn/models/inclusionAI/Ming-Lite-Omni-1.5