AIGCPanel 的用户们,欢呼吧!全新 1.1.0 版本带着满满的诚意与惊喜正式上线,每一项更新都直击用户痛点,力求为大家带来更加便捷、高效且智能的 AI 数字人创作体验。
AIGCPanel 新版本带着一堆硬核功能来了!用过的都说效率翻倍
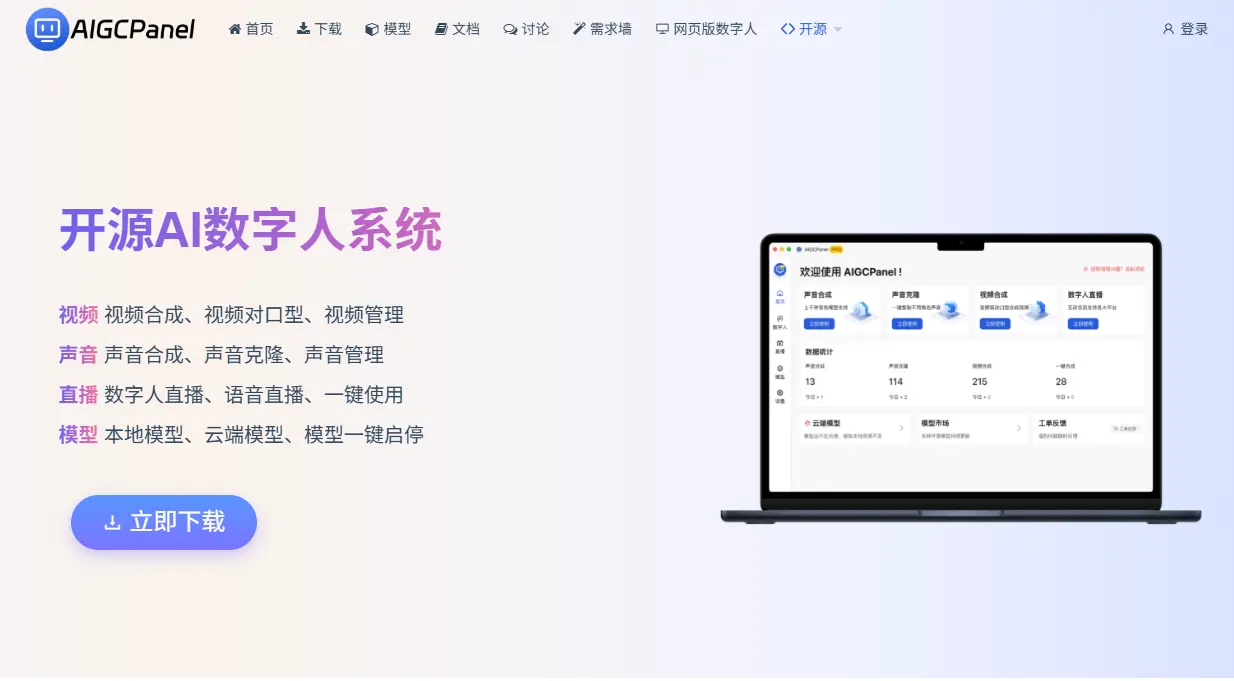
软件介绍
AigcPanel是一个简单易用的一站式免费开源AI数字人系统,小白也可使用。 支持智能直播、视频合成、声音合成、声音克隆,简化本地模型管理、一键导入和使用AI模型。
禁止使用本产品进行违法违规业务,使用本软件请遵守中华人民共和国法律法规。
重磅更新!
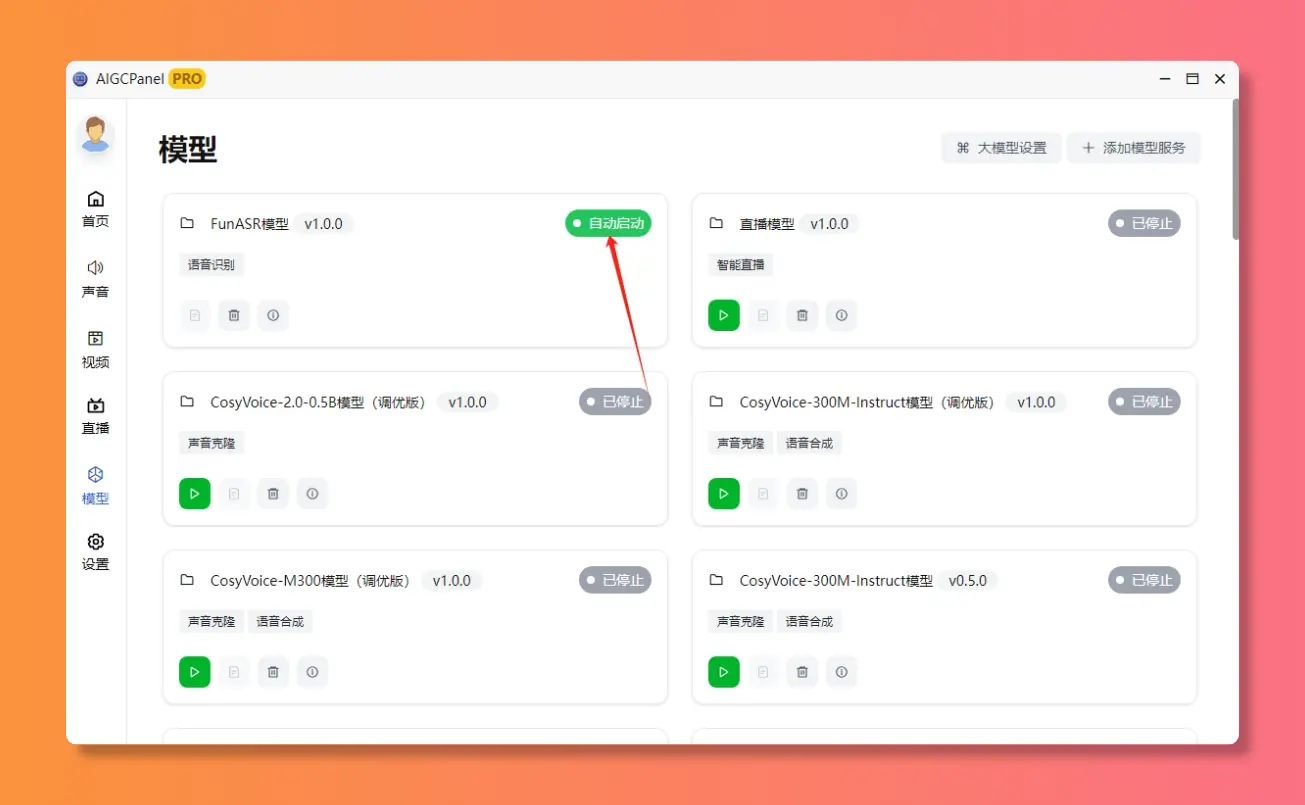
模型能自启动了!设为自启动后不用手动点,打开就干活文件存哪自己定!
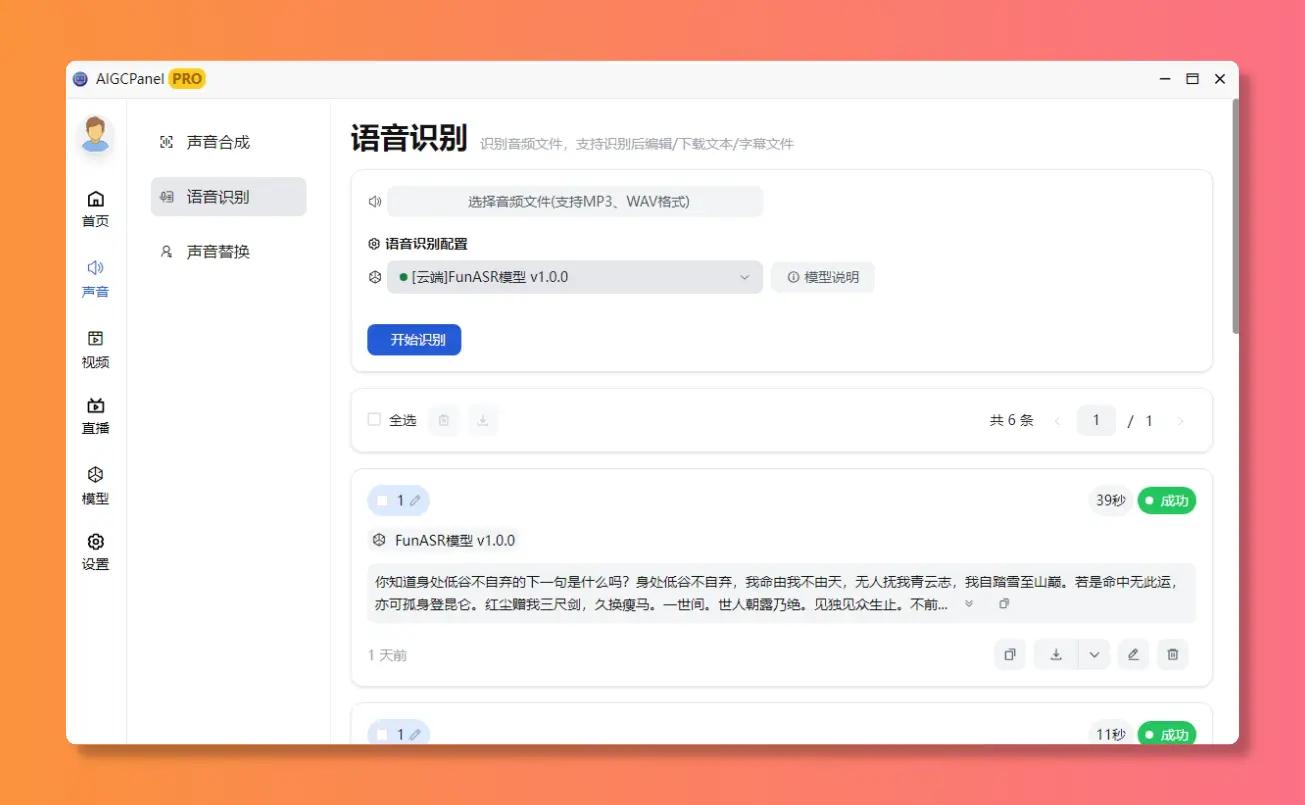
自定义存储路径,找文件再也不用翻遍电脑新增语音识别功能!
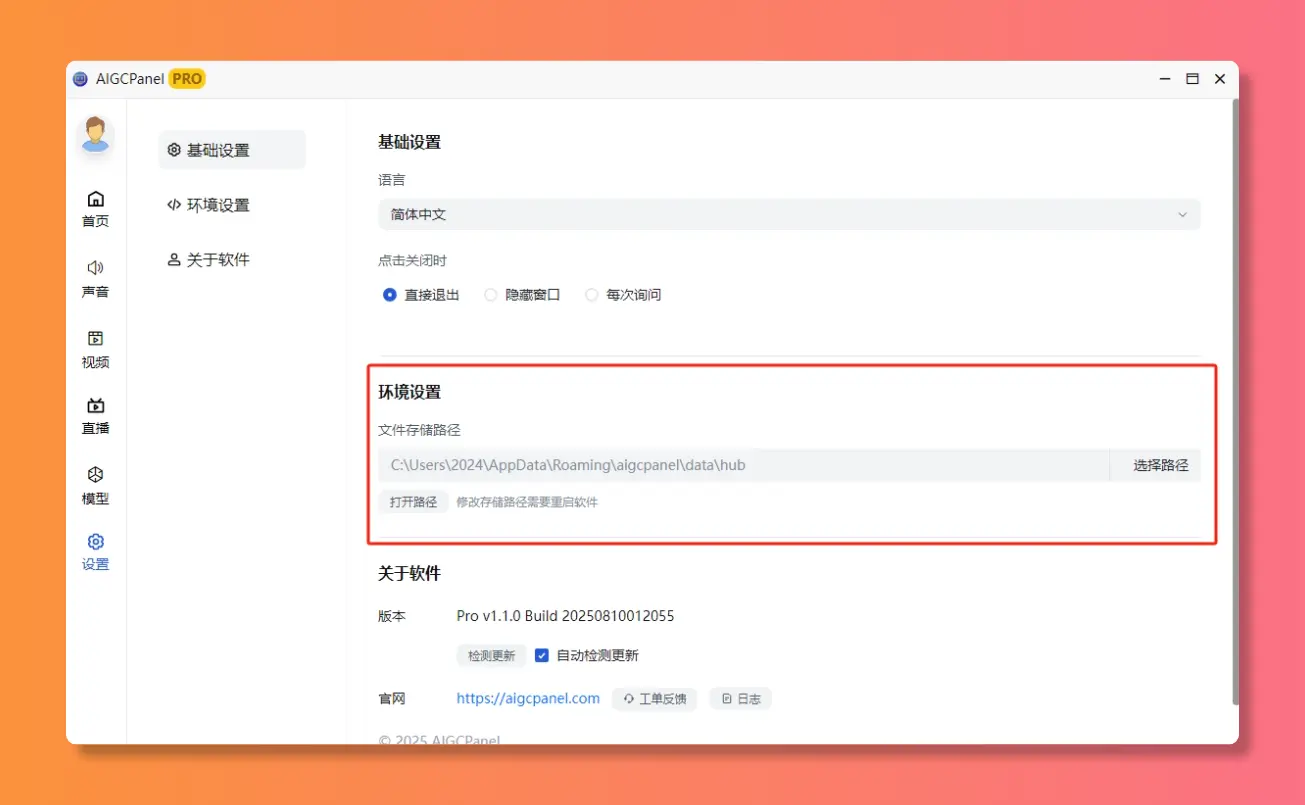
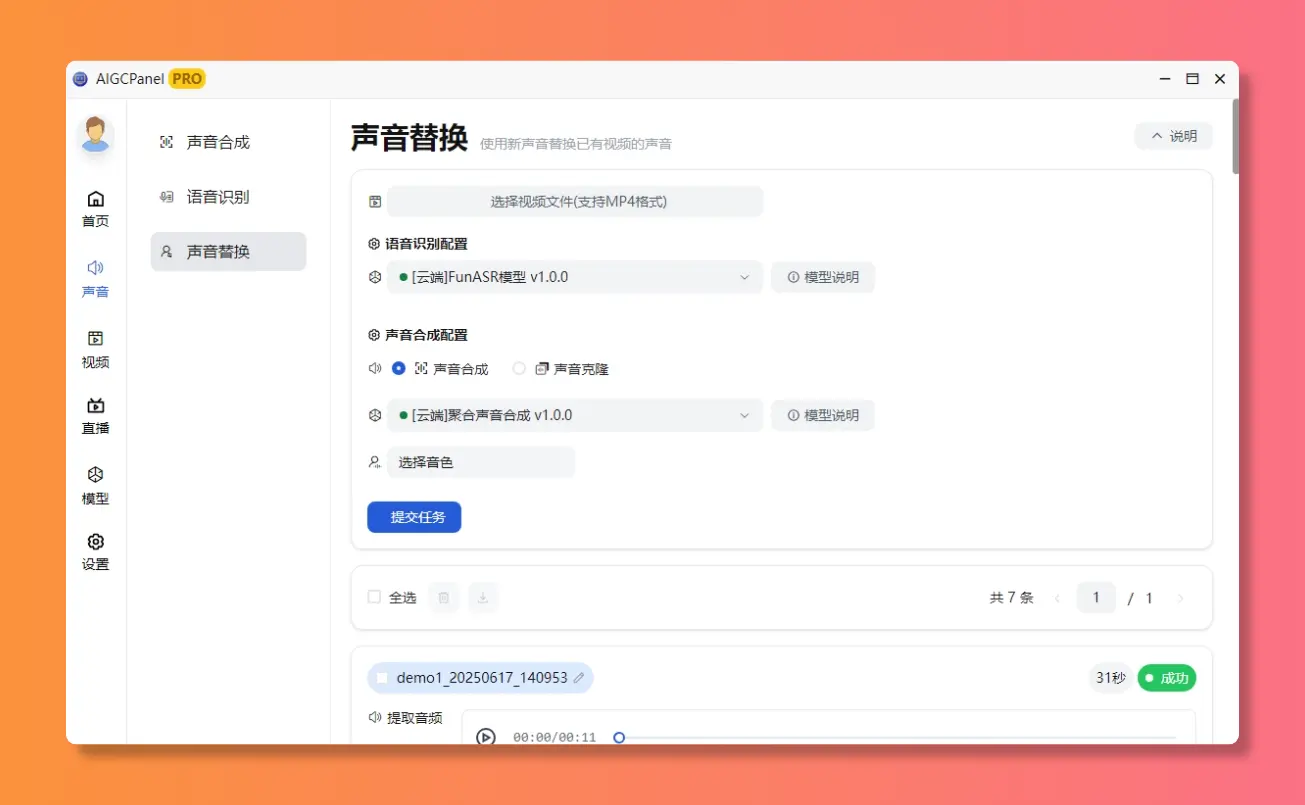
语音秒转文字,开会记笔记神器声音替换上线!
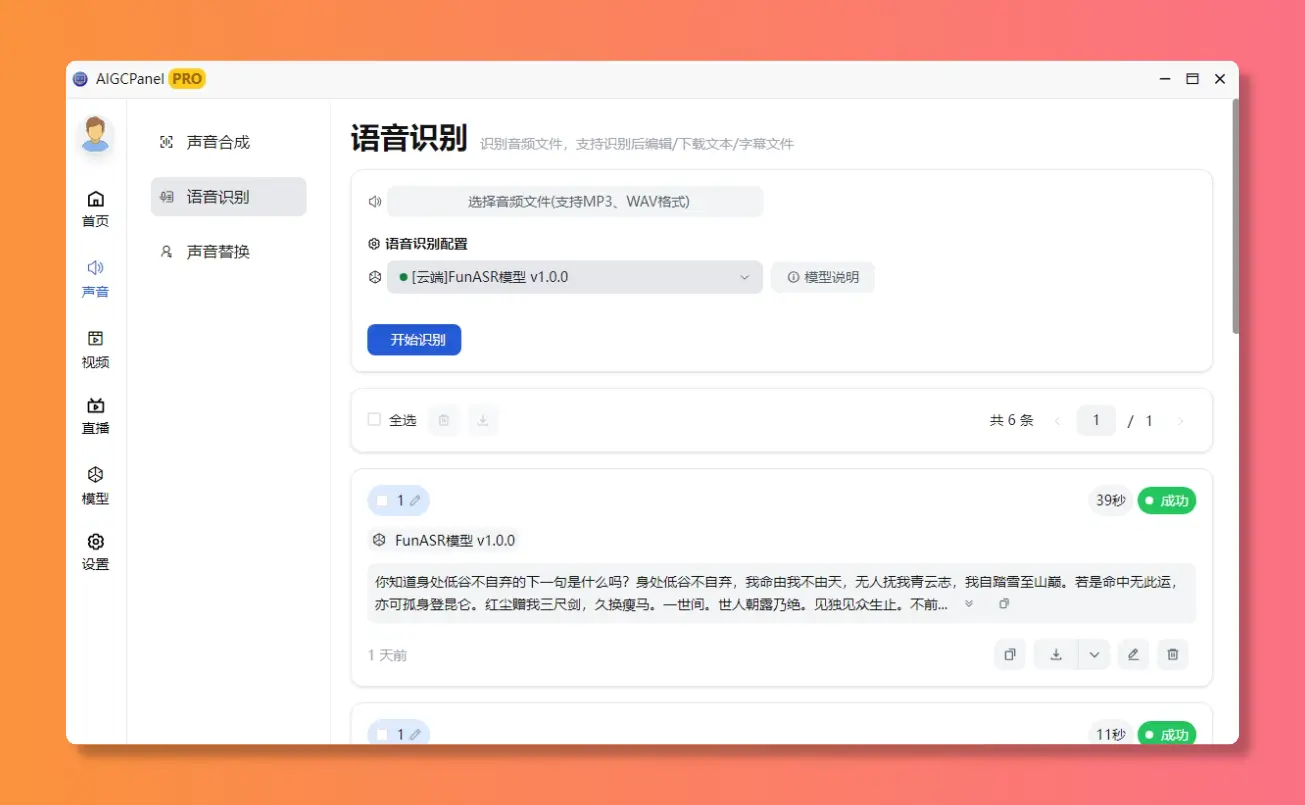
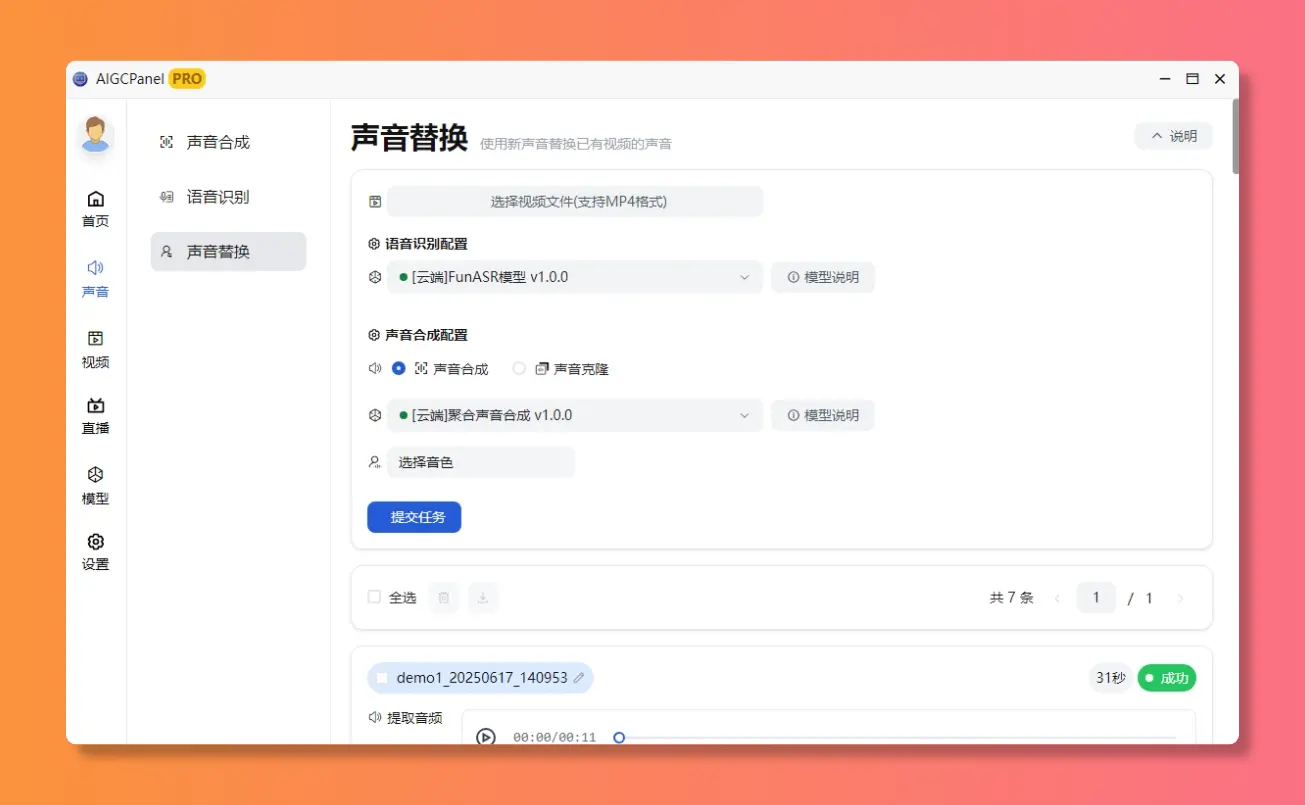
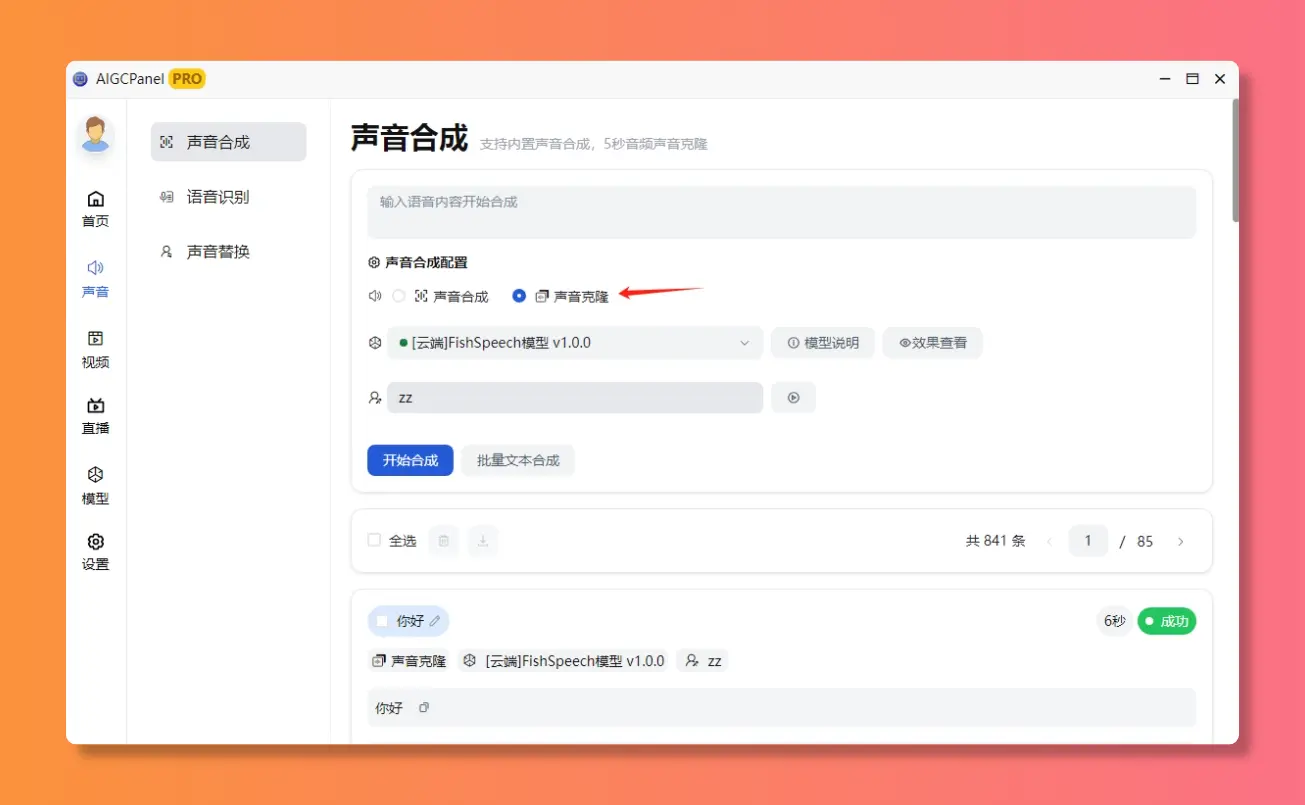
想给视频换个声线?一键搞定
为什么选择 AigcPanel?
✅ 零门槛操作:本地部署操作简单,小白也能秒变 AI 大神!
✅ 云端算力:免部署,高性能模型即点即用!
✅ 免费模型:本地搭建,一键快速启动!
✅ VIP 专属模型:解锁更高精度、更强大功能!
功能特性
支持视频数字人合成,支持视频画面和声音换口型匹配
支持语音合成、语音克隆,多种声音参数可设置
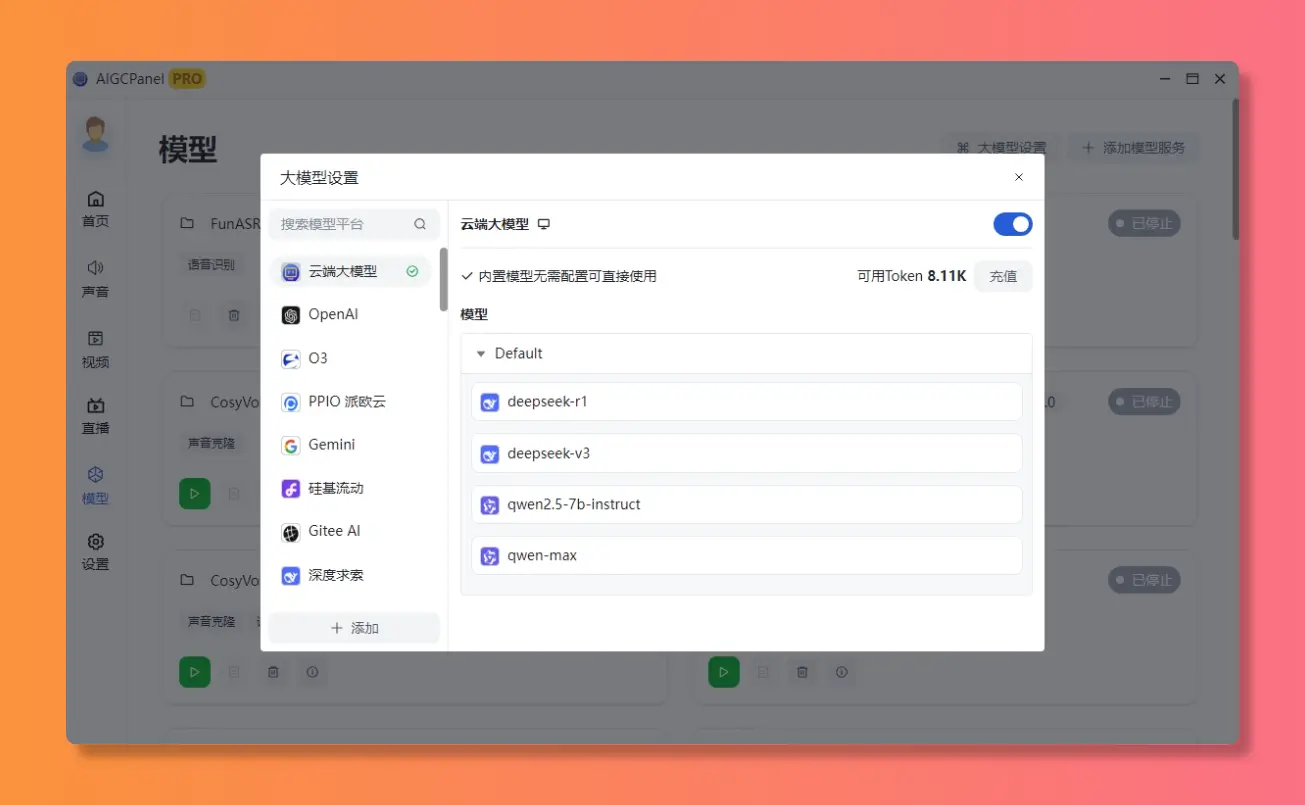
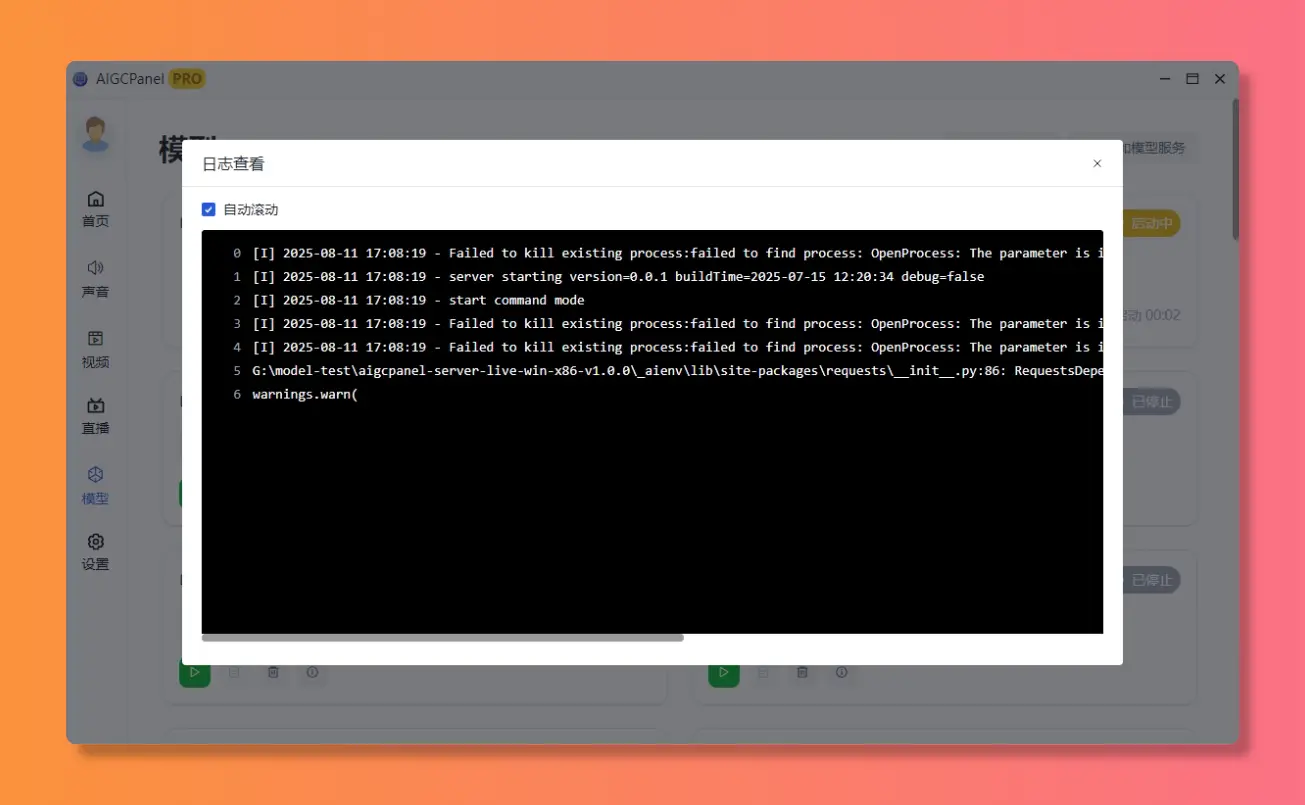
支持多模型导入、一键启动、模型设置、模型日志查看
支持国际化,支持简体中文、英语支持本地免费多种模型一键启动包。
本地模型
视频模型:MuseTalk
视频模型:Wav2Lip
视频模型:LatentSync
语音模型:CosyVoice-300M
语音模型:CosyVoice-2.0-0.5B
语音模型:CosyVoice-300M-Instruct
语音模型:Fish Speech
语音模型:Spark-TTS
语音模型:IndexTTS
语音模型:GPT-SoVITS
语音模型:Funasr【新增】
视频模型:Wav2lip384(调优版)
语音模型:CosyVoice-300M模型(优化版)
视频模型:Heygem(调优版)
语音模型:IndexTTS(直播版)
直播模型:智能直播模型
云端模型快速生成:
声音模型:[云端]聚合声音合成模型
声音模型:[云端]CosyVoice2-0.5B模型
声音模型:[云端]CosyVoice-M300模型
声音模型:[云端]FishSpeech模型
声音模型:[云端]Step-Audio-TTS-3B模型
语音模型:[云端]Funasr模型【新增】
视频模型:[云端]MuseTalk模型
视频模型:[云端]LatentSync模型
视频模型:[云端]Wav2Lip模型
视频模型:[云端]Heygem模型
版本更新 v1.1.0【2025-08-11】
语音识别,声音替换,模型自启动,应用工具上线
新增:模型增加是否自启动属性,自启动模型无需手动启动
新增:声音和视频界面拆分
新增:窗口顶部点击最大化
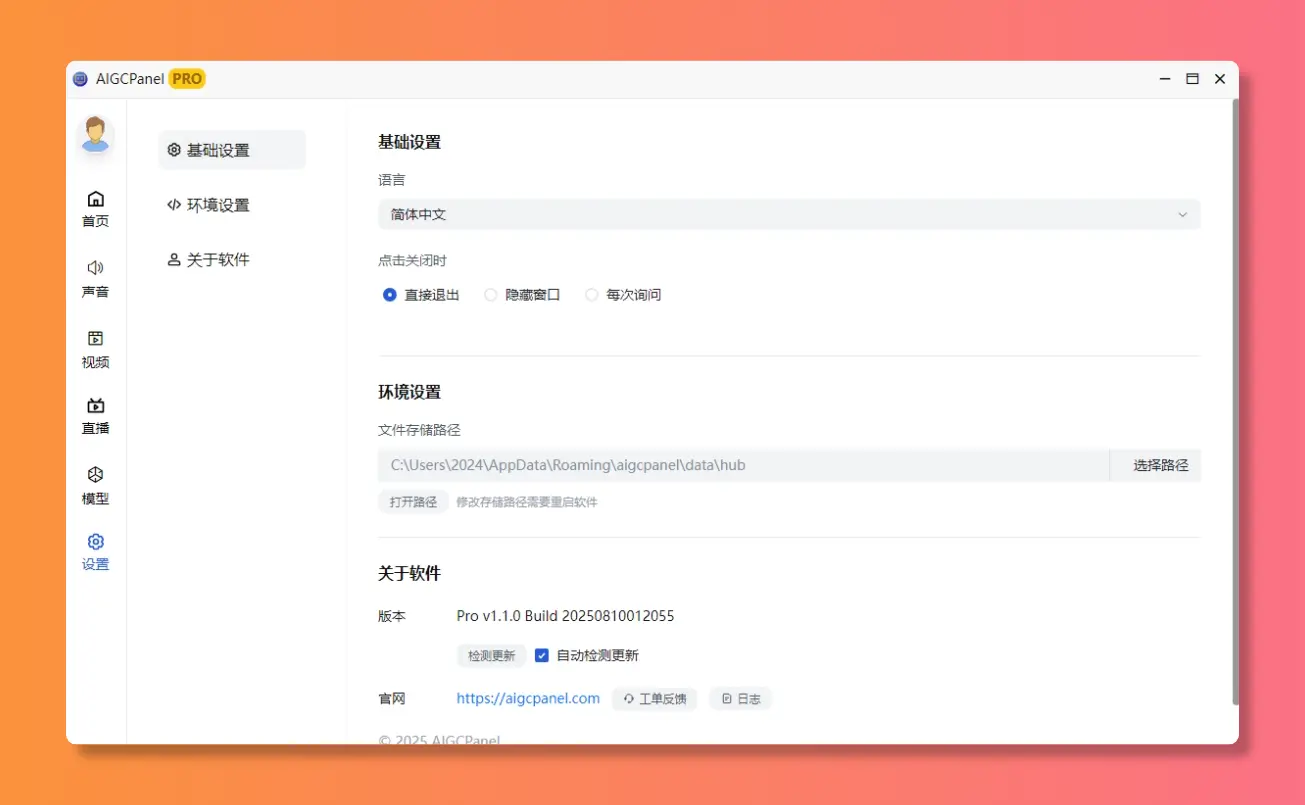
新增:文件存储路径可配置,支持自定义文件存储路径
新增:声音合成自定义声音支持 mp3 格式
新增:语音识别功能
新增:声音替换功能
新增:首页增加应用工具
优化:任务运行调度底层重构
优化:文案拆分,功能定位清晰化
优化:界面显示优化
优化:模型重置可直达模型充值界面
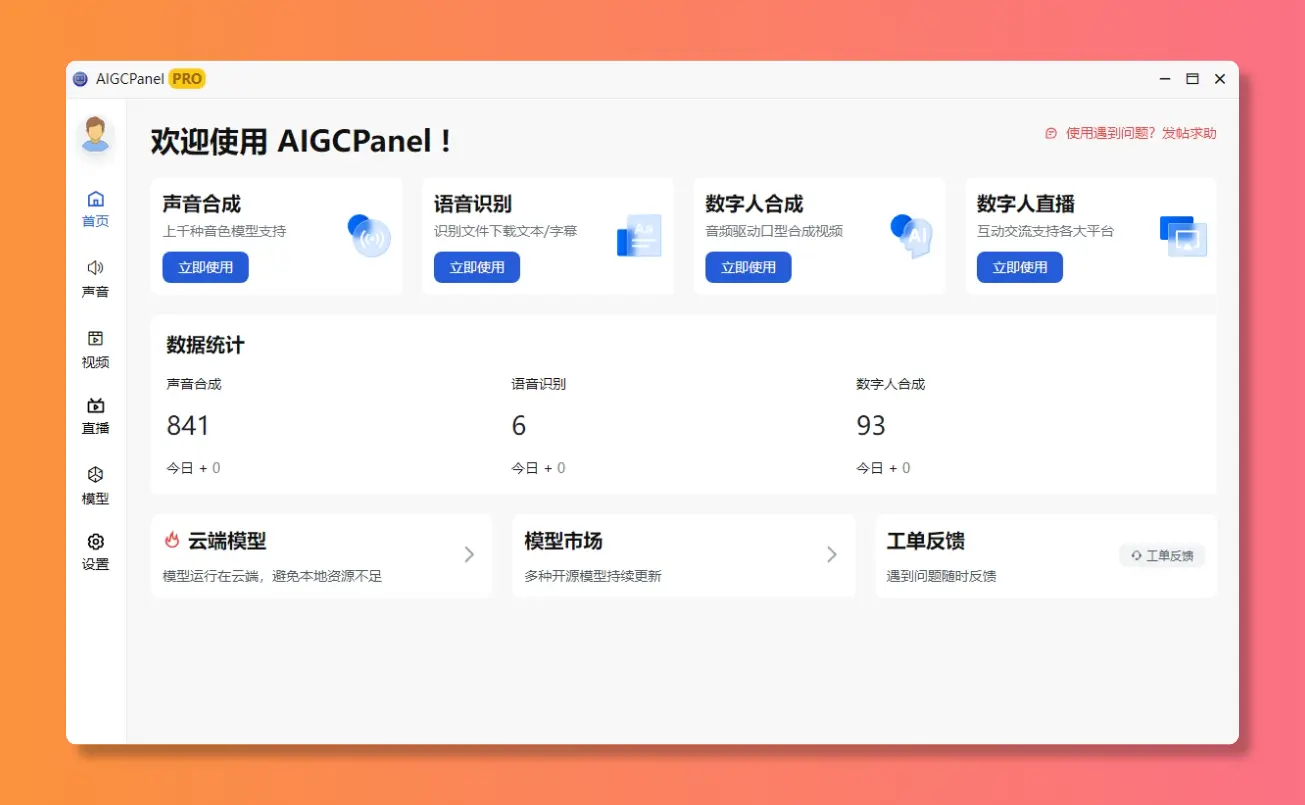
功能预览
声音合成
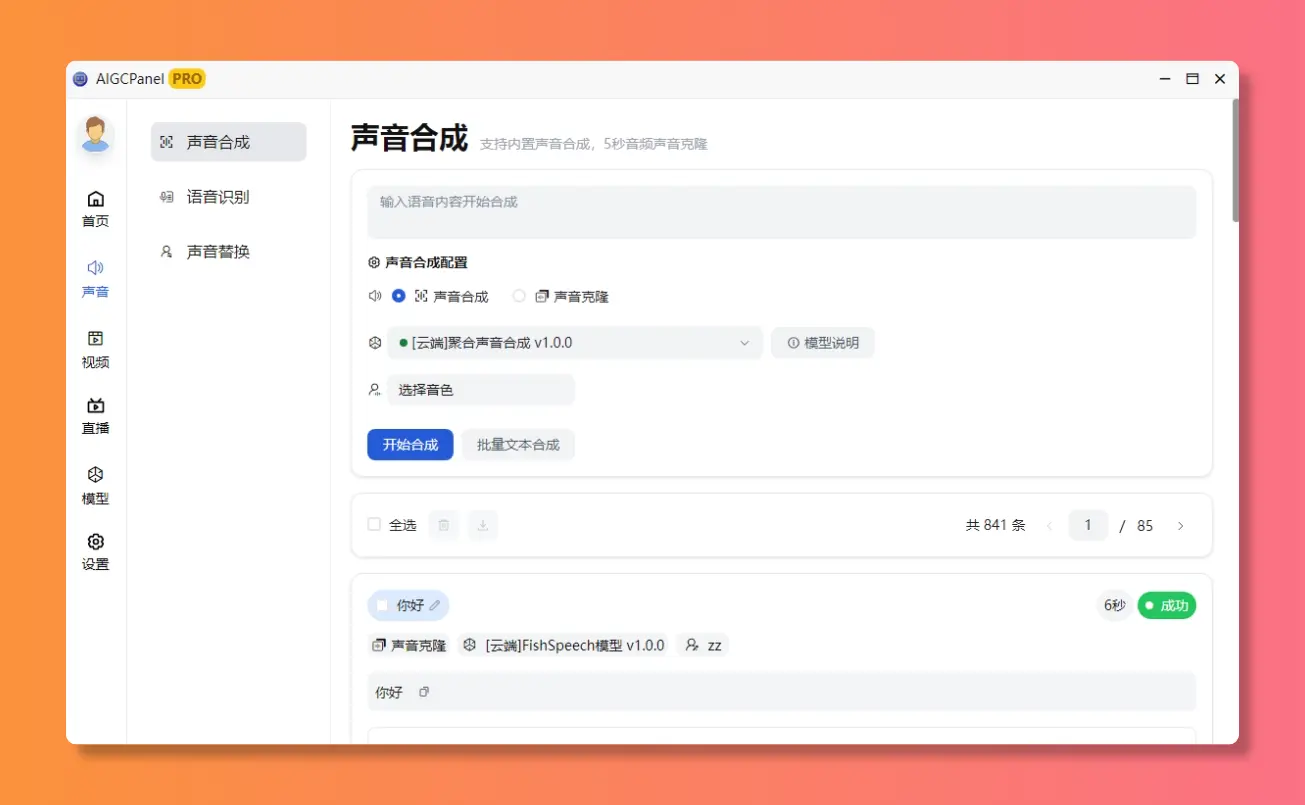
音色管理
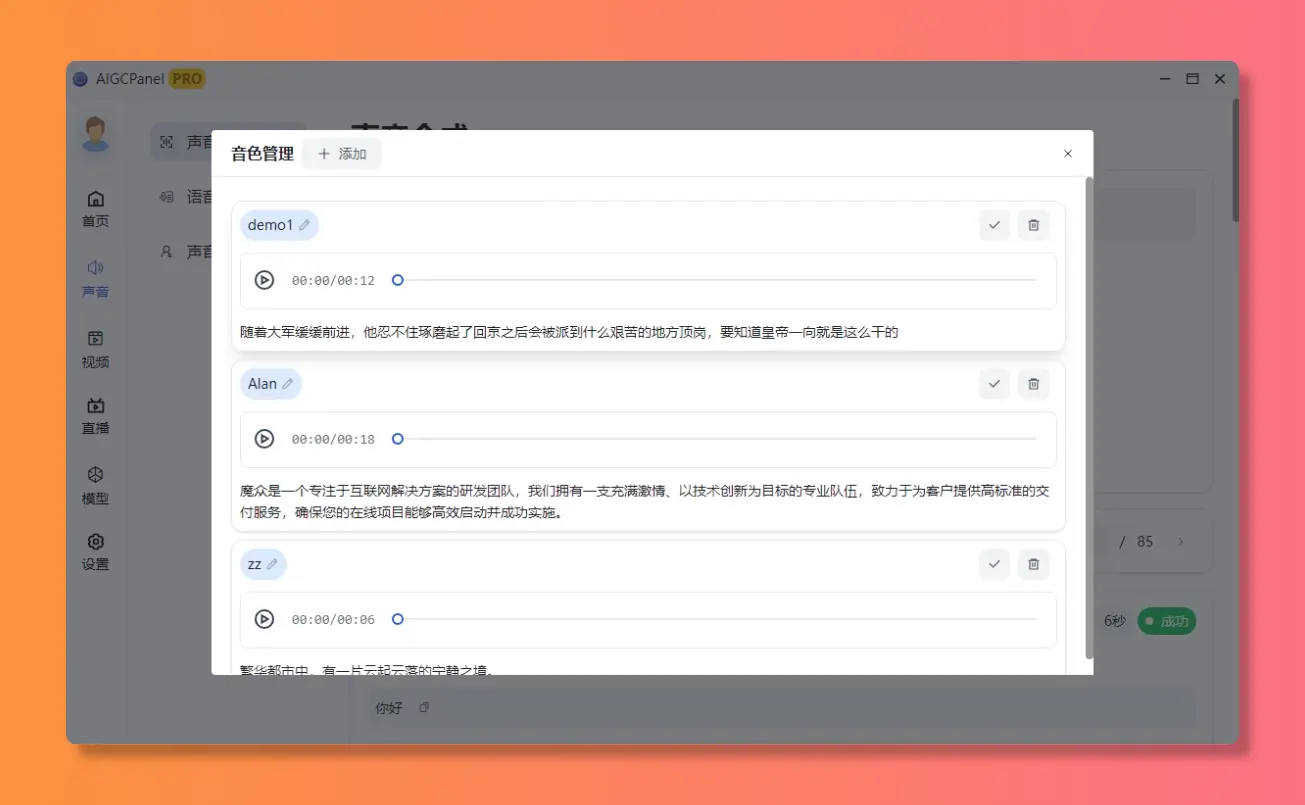
声音克隆
声音识别
声音替换
数字人形象
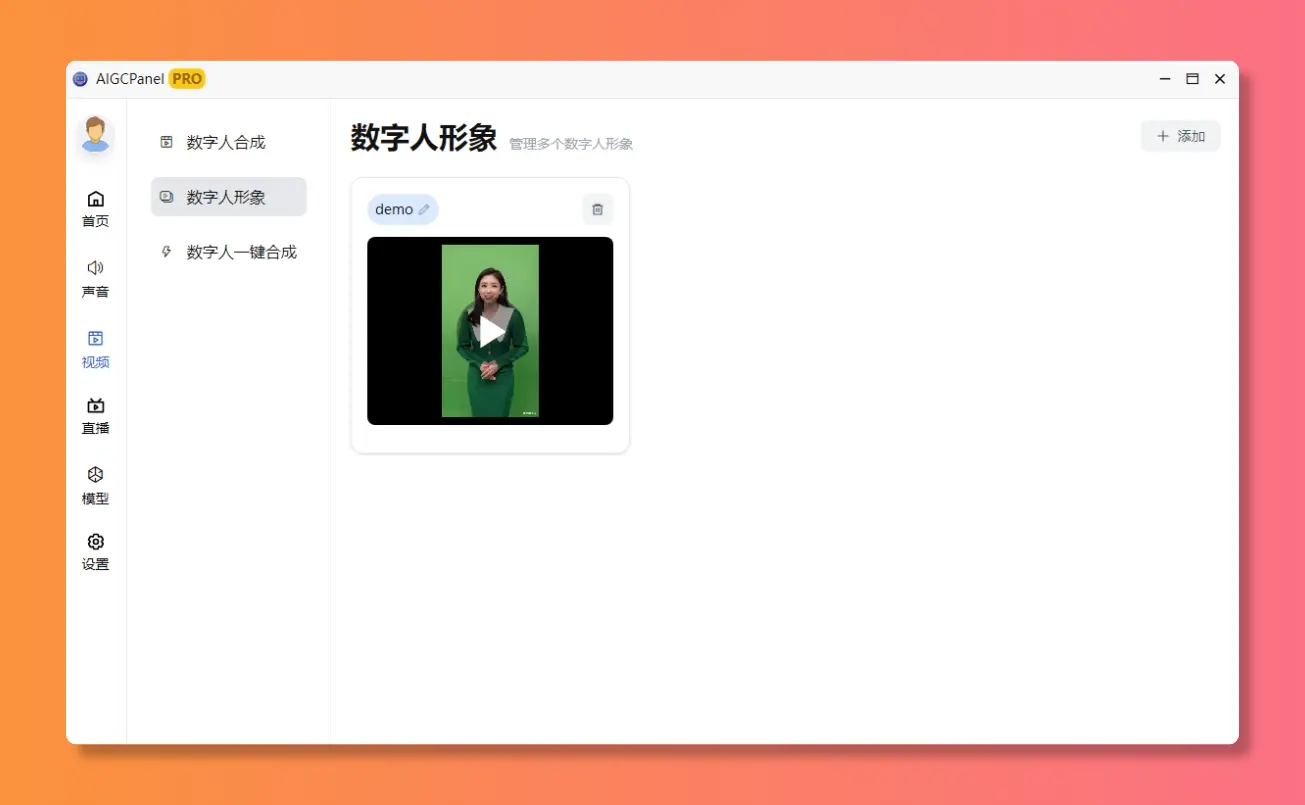
数字人合成
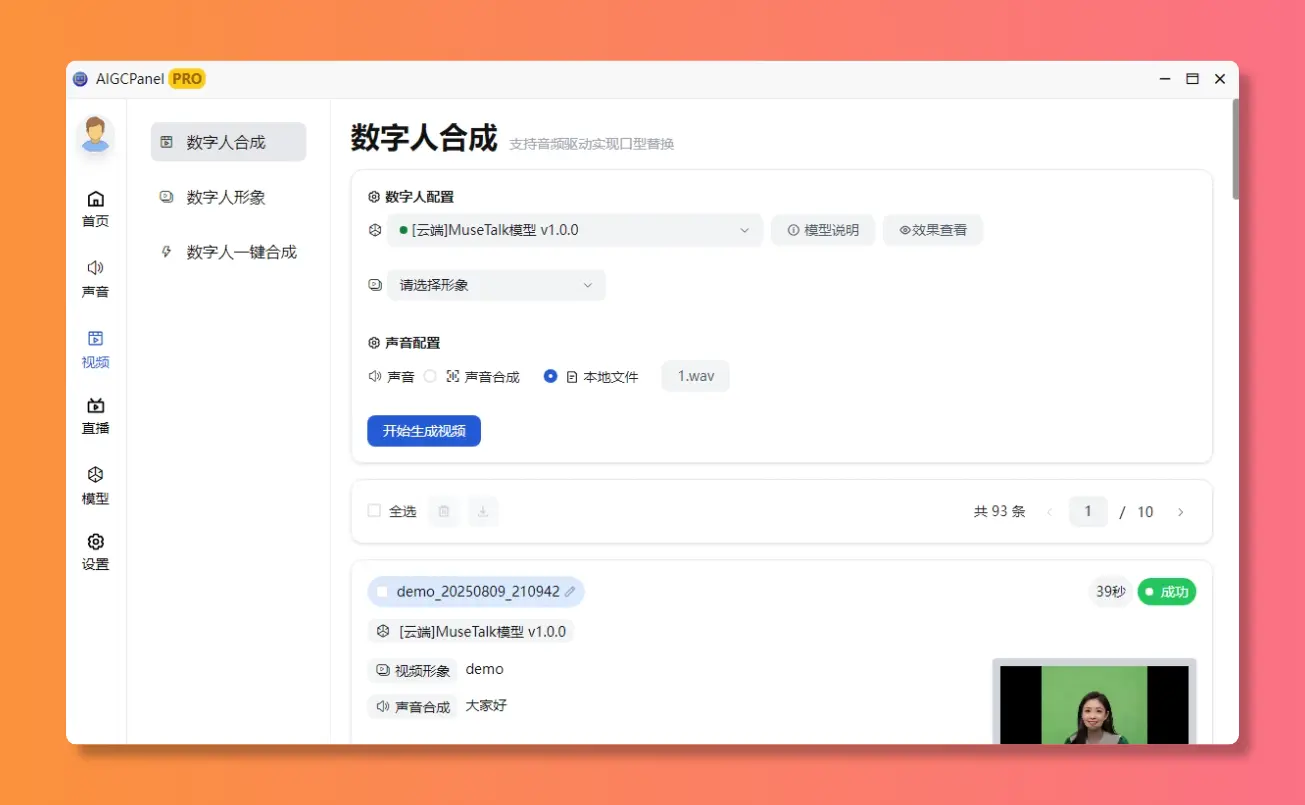
数字人一键合成
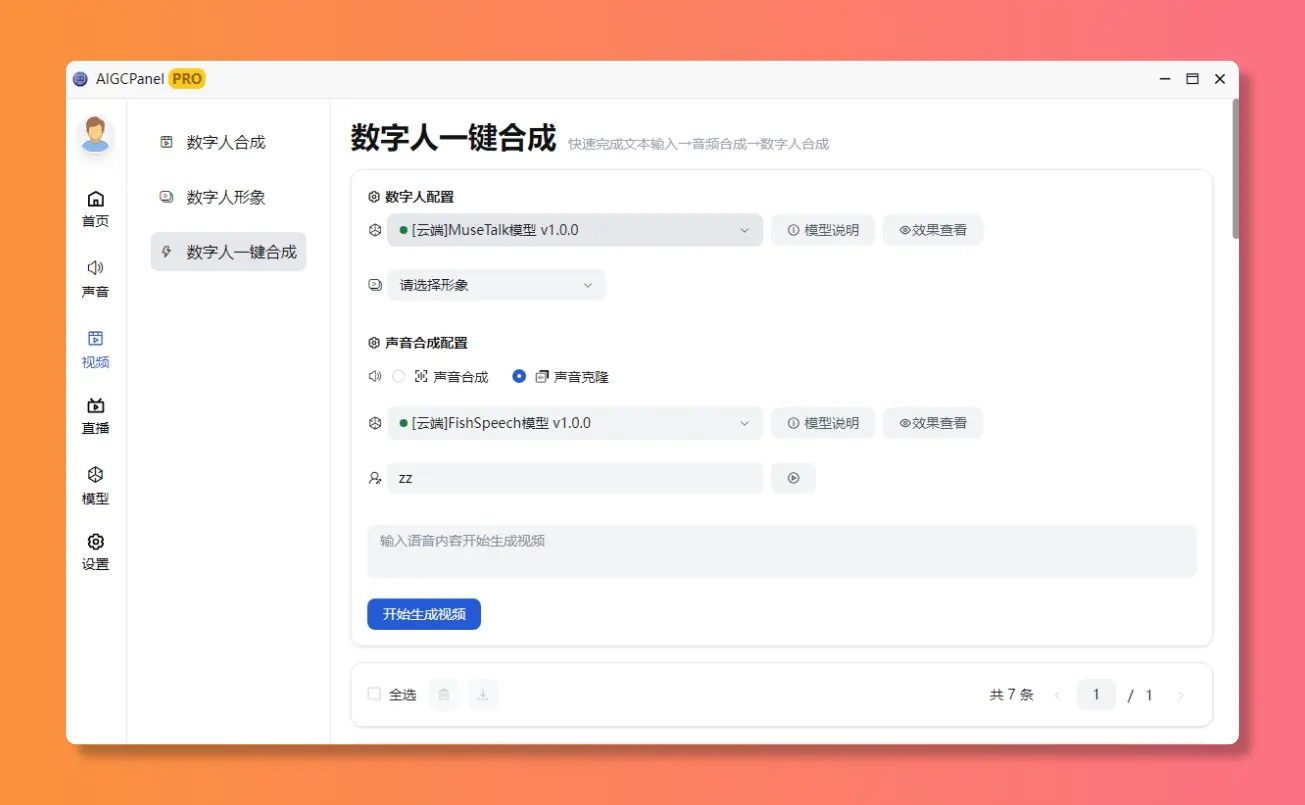
直播知识库
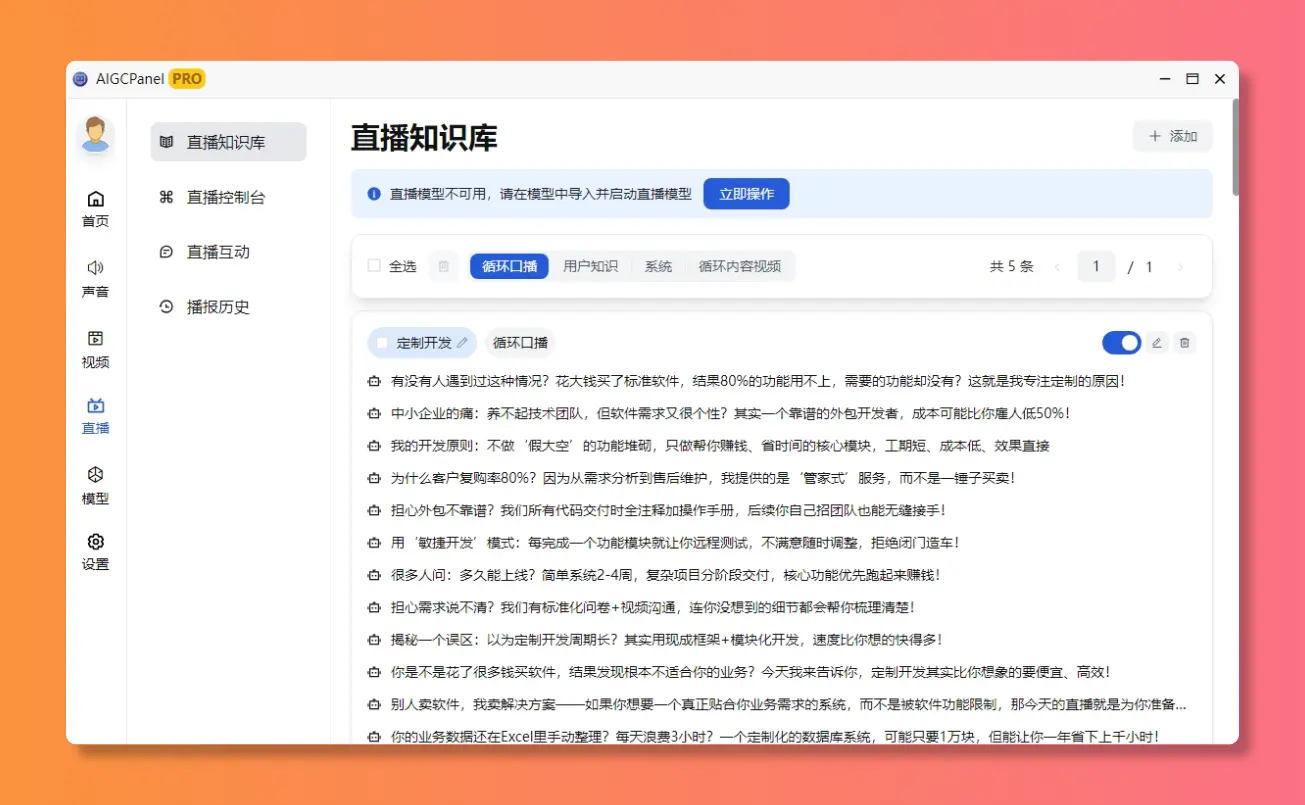
直播控制台
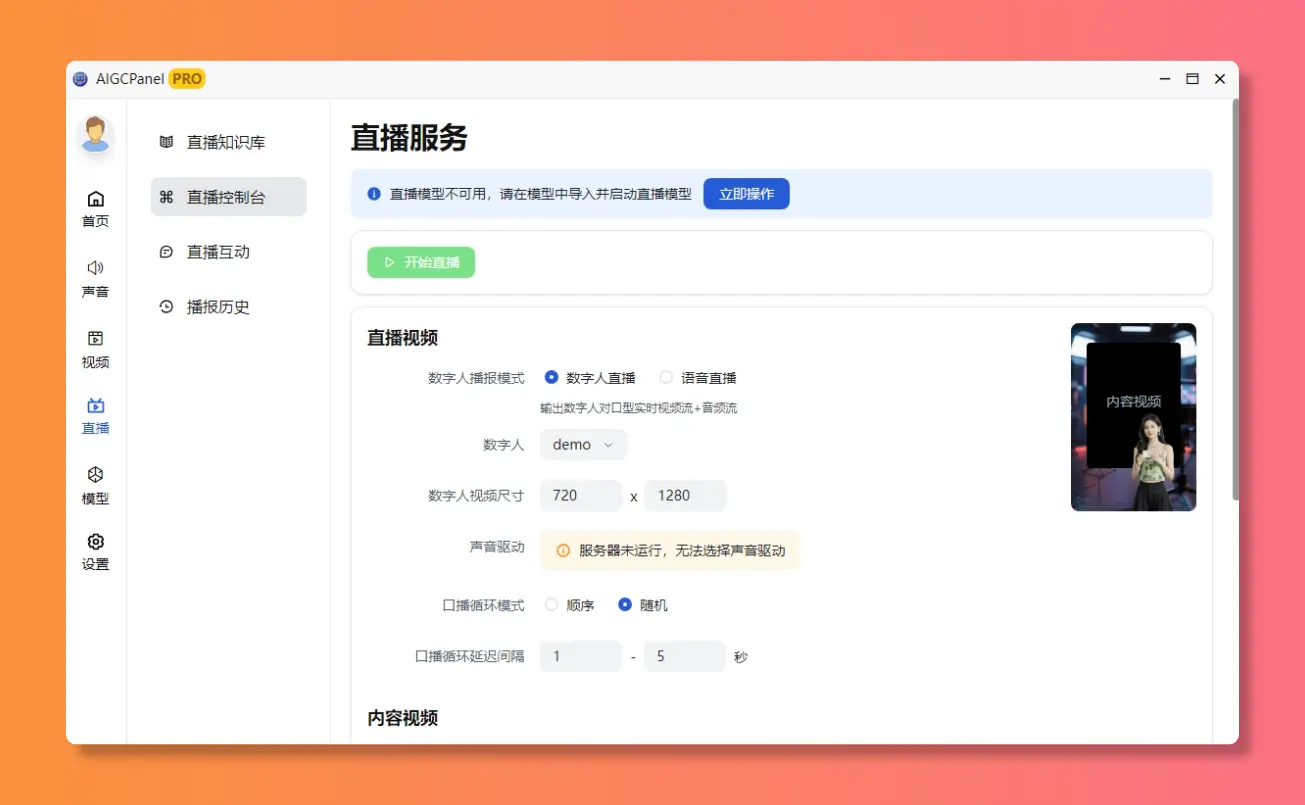
直播互动
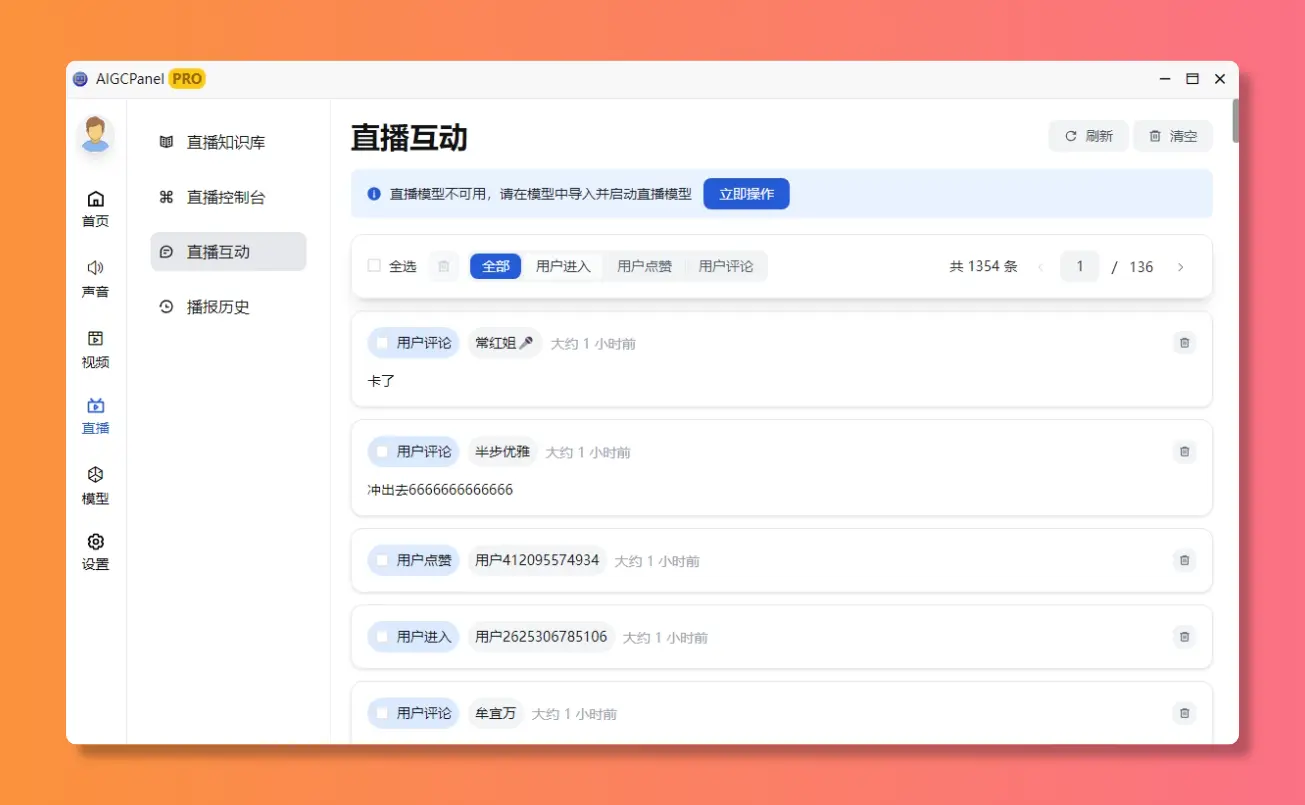
播报历史
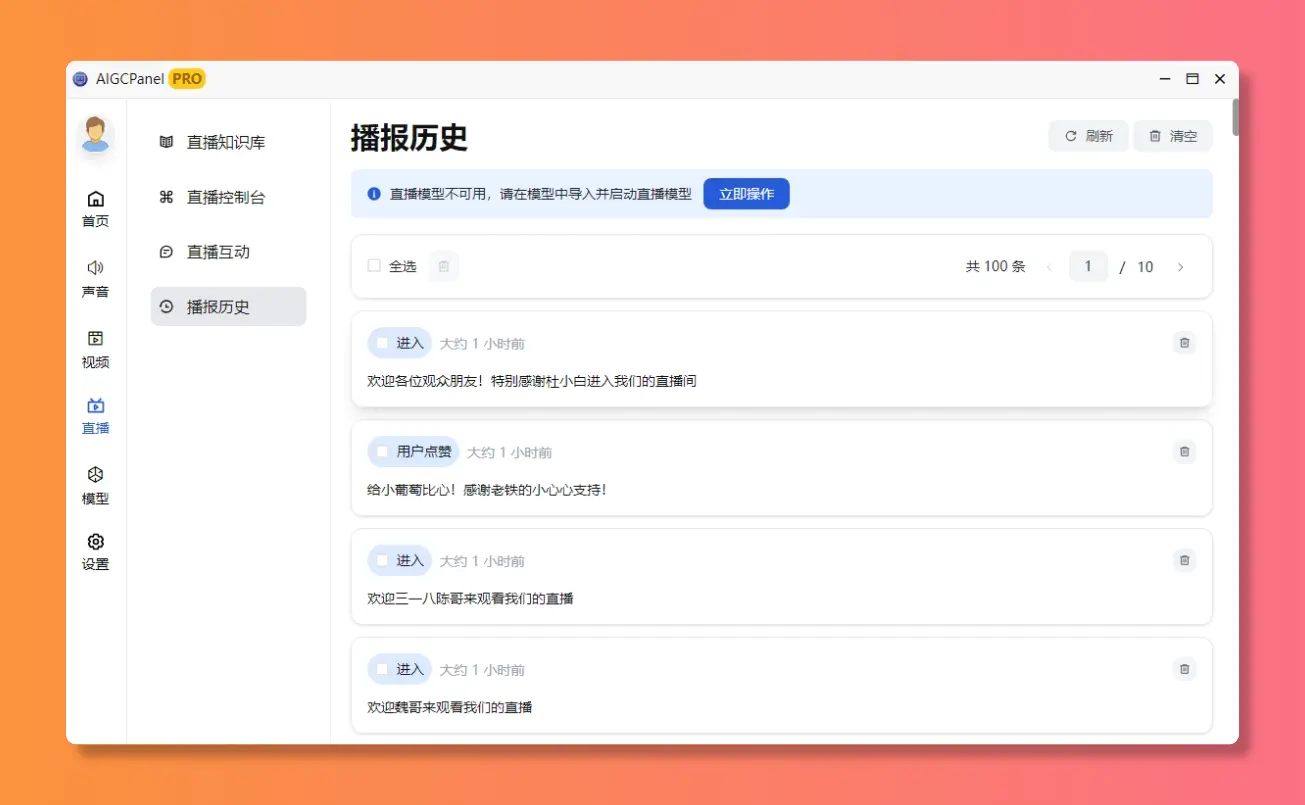
模型添加
大模型设置
模型日志
设置
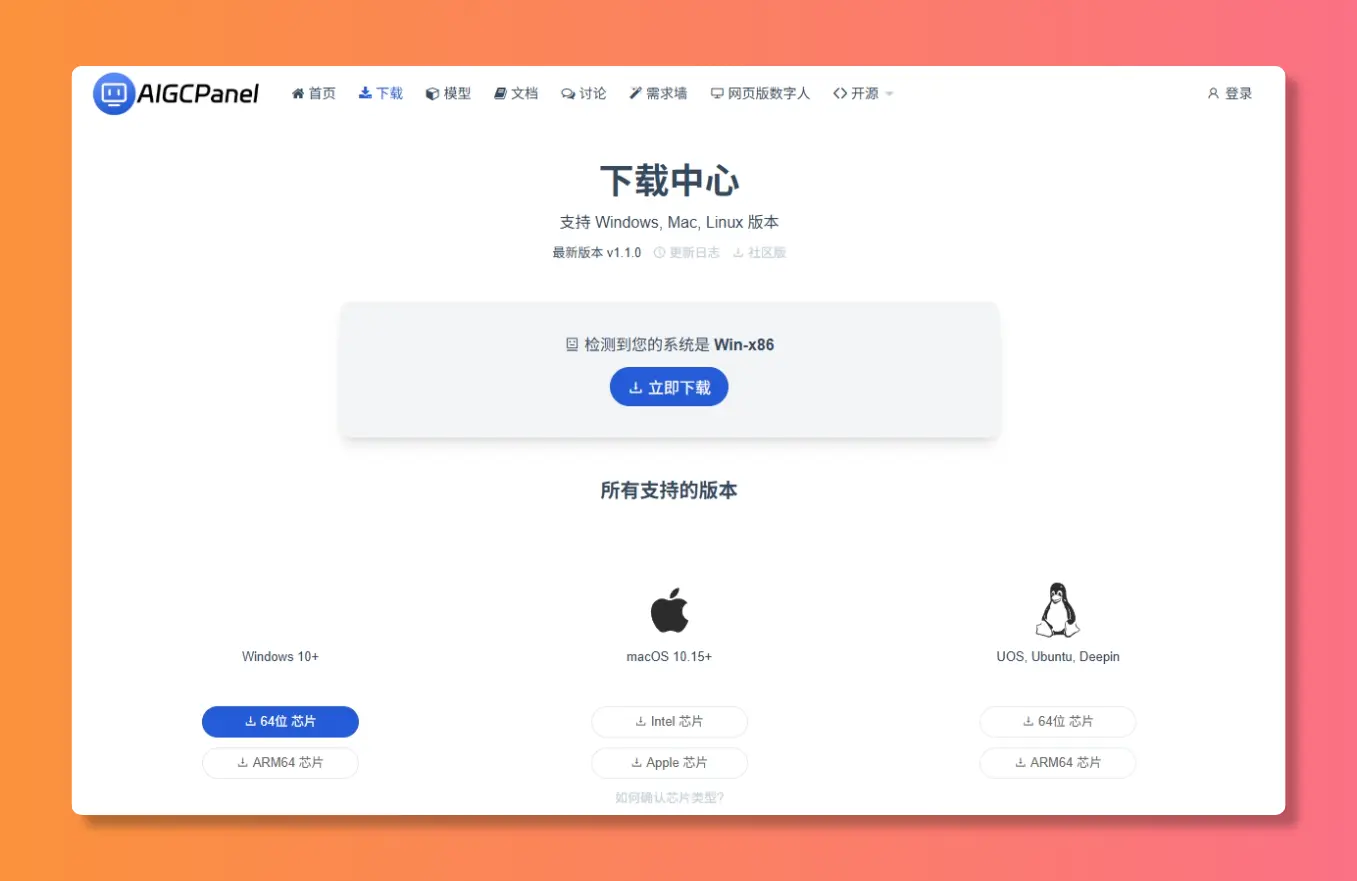
安装使用
Windows / Mac
访问 https://aigcpanel.com 下载安装包,一键安装即可
安装完成后,打开软件,下载模型一键启动包,即可使用。
相关链接
官网:
https://aigcpanel.com
Github:
https://github.com/modstart-lib/aigcpanel
Gitee:
https://gitee.com/modstart-lib/aigcpanel
Gitcode:
https://gitcode.com/modstart-lib/aigcpanel
License
Apache-2.0