谷歌宣布其Gemini API中的URL Context工具已正式支持直接抓取 URL 内容,无需额外脚本或中间步骤。
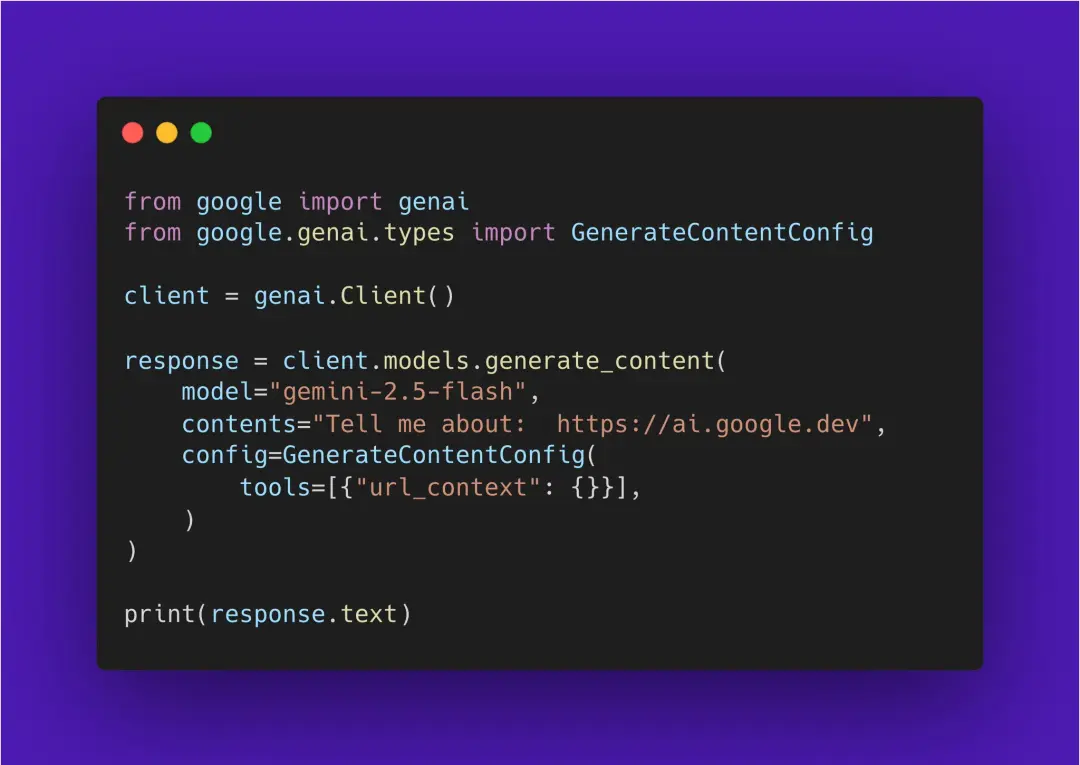
Gemini API 提供了 URL Context 功能,允许你在请求中直接嵌入网页链接,模型会自动访问并解析网页内容。支持的内容类型包括:
- 文本网页(HTML、JSON、TXT 等)
- PDF 文件
- 图片(PNG、JPEG、WebP 等)
不支持的内容:YouTube 视频、Google Docs、付费墙内容等。
✅ 使用示例(Python SDK)
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
"总结这篇文章的内容:",
types.Part.from_uri(
uri="https://example.com/article",
mime_type='text/html'
)
]
)
print(response.text)
使用限制
- 每次最多支持 20 个 URL
- 单个 URL 内容大小上限为 34MB
- 抓取内容会计入 输入 Tokens 费用
如果你使用 Gemini CLI,也可以通过 web_fetch 工具快速抓取网页,例如:
gemini-cli web-fetch --prompt "总结 https://example.com/article 的主要内容"
该工具会自动识别提示中的 URL 并调用 Gemini API 抓取内容。
如你正在开发基于 Gemini 的应用,URL Context 功能已足够替代传统的爬虫或 HTML 解析器,大幅提升开发效率。
相关链接
https://ai.google.dev/gemini-api/docs/url-context
https://colab.sandbox.google.com/github/google-gemini/cookbook/blob/main/quickstarts/Grounding.ipynb#url-context