腾讯 AI Lab 推出一项名为 AudioGenie 的新型无训练多智能体系统,为多模态到多音频(MM2MA)生成领域带来重大突破。
该系统能从视频、文本、图像等多模态输入中,精准合成音效、语音、音乐、歌曲等多种音频,有效解决了该领域长期面临的高质量配对数据稀缺、多任务学习框架薄弱等核心挑战。
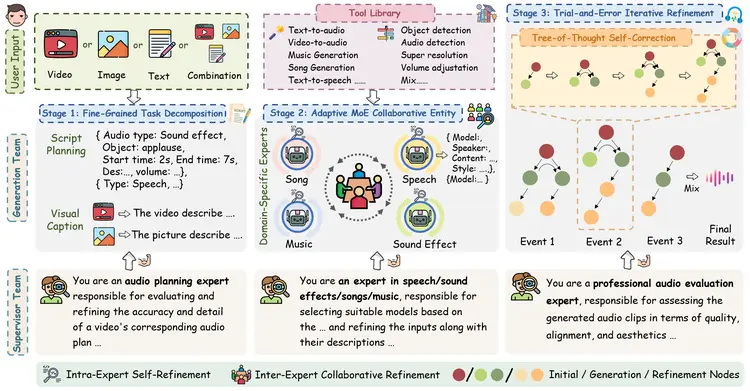
AudioGenie 框架如下:
https://audiogenie.github.io/
AudioGenie 采用双层架构,由生成团队与监督团队组成。生成团队通过细粒度任务分解和自适应混合专家(MoE)协作机制,实现对多模态输入的深度理解与动态模型选择,并借助试错迭代优化模块完成自我修正;监督团队则通过反馈循环确保音频的时空一致性并验证输出质量。
此外,研究团队还构建了首个 MM2MA 任务基准数据集 MA-Bench,包含 198 个带多类型音频标注的视频。实验表明,AudioGenie 在 8 项任务的 9 个指标中均达到当前最优或可比性能,用户研究进一步证实其在音频质量、准确性、上下文对齐及美感上的显著优势,为跨模态音频生成应用开辟了新路径。