ElevenLabs 正式推出专为异步场景设计的 Eleven v3 Alpha API,号称是其迄今最具表现力的文本转语音模型。
其功能包括对话模式、支持无限数量的说话人、覆盖 70 多种语言,并可通过音频标签实现更精细的语音与情感控制。
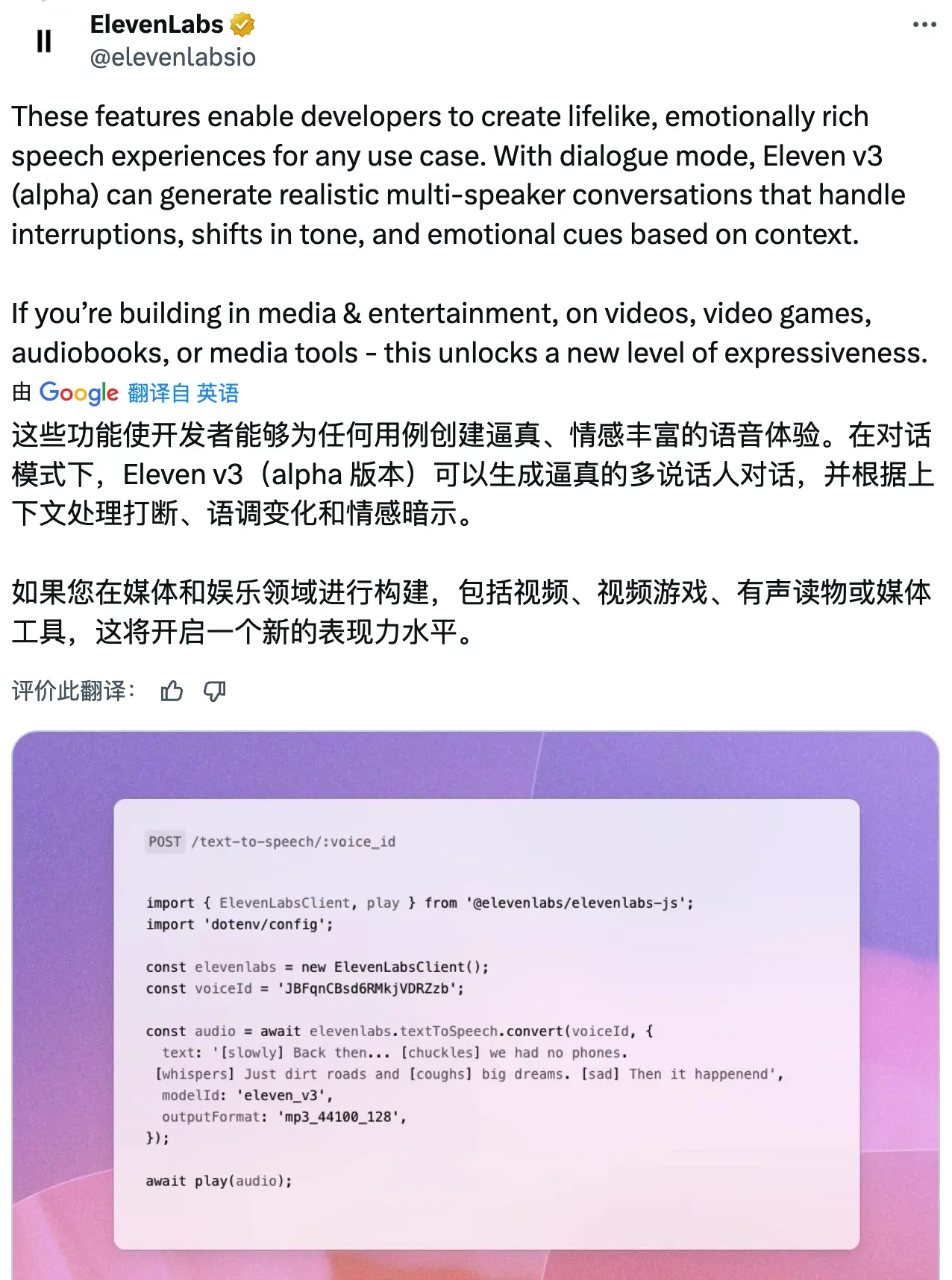
根据官方介绍,这些功能使开发者能够为任何用例创建逼真、情感丰富的语音体验。在对话模式下,Eleven v3(alpha 版本)可以生成逼真的多说话人对话,并根据上下文处理打断、语调变化和情感暗示。如果在媒体和娱乐领域进行构建,包括视频、视频游戏、有声读物或媒体工具,这将开启一个新的表现力水平。