书生发布了最新的视觉模型 InternVL 3.5 全系列模型,从 1B 到 241B 共 8 个尺寸。
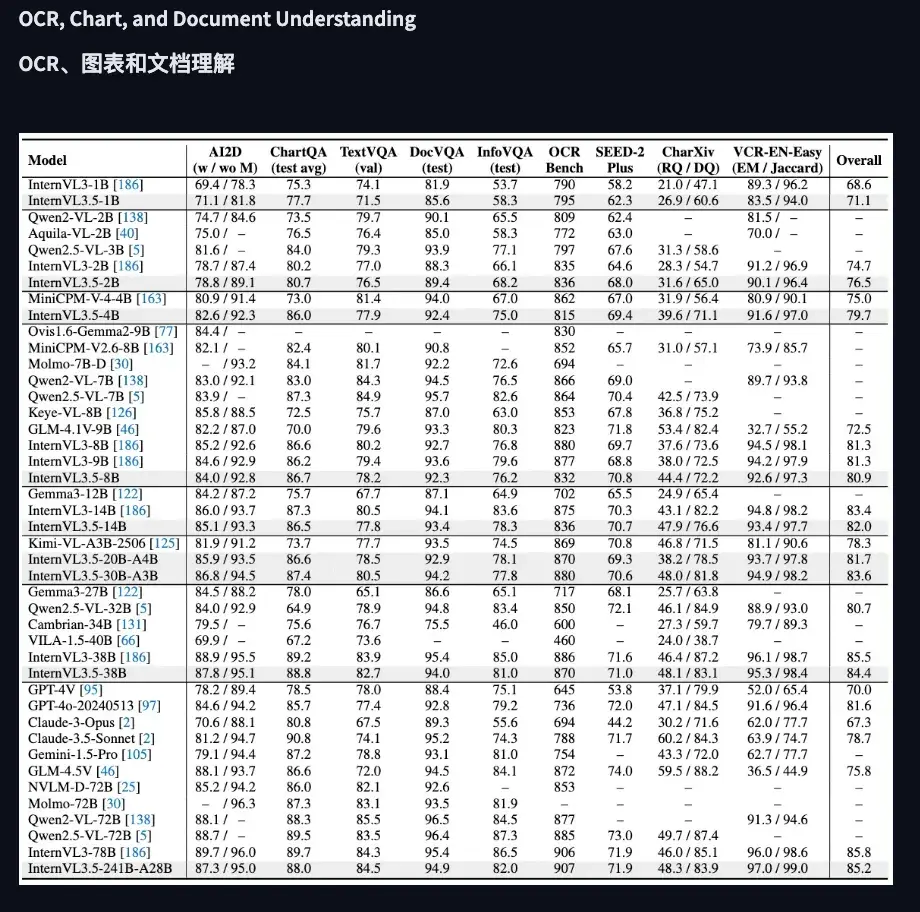
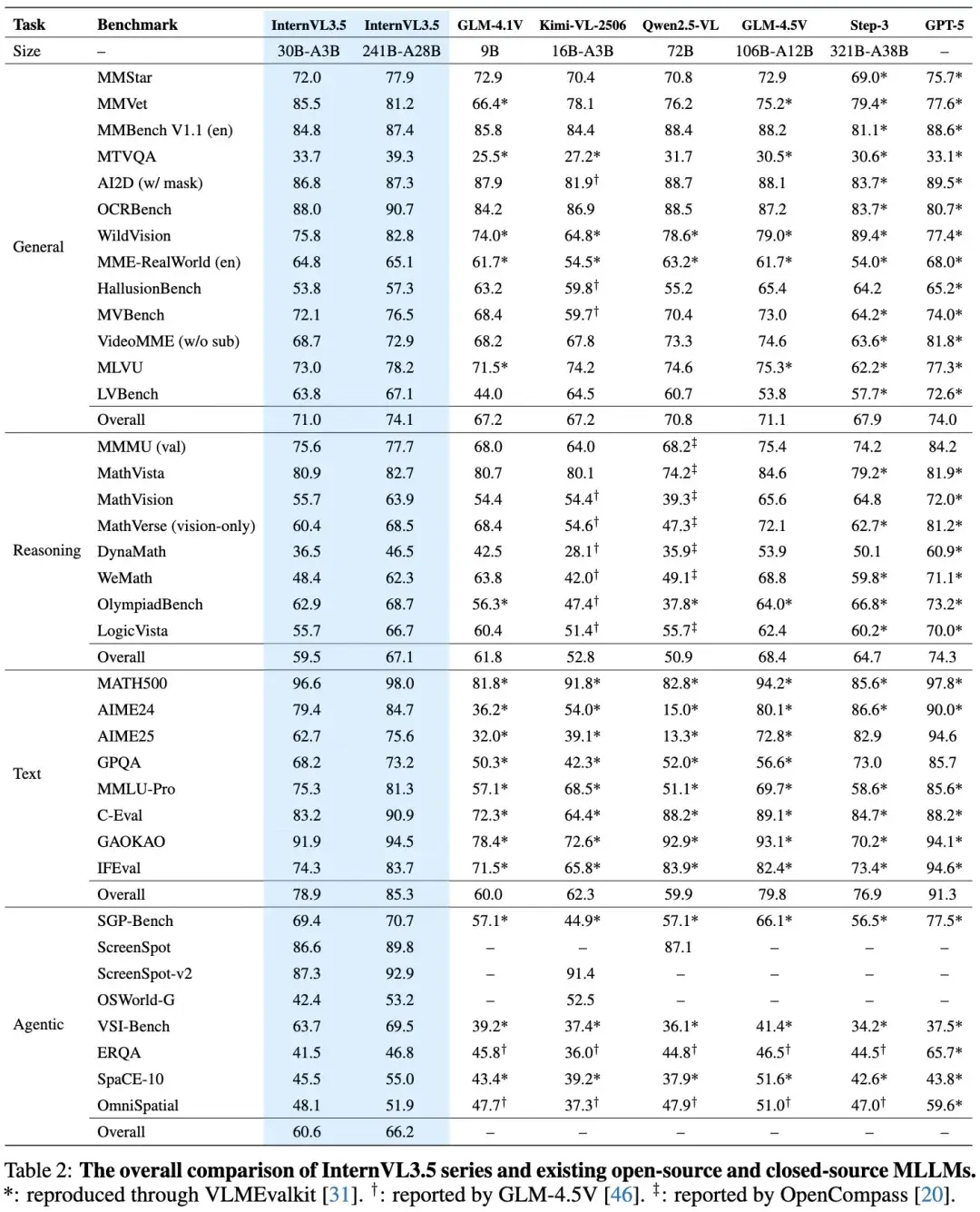
根据评测结果,书生 3.5 最高尺寸 241B 在视觉模型里的表现仅次于商业版的 GPT-5 和 Gemini 2.5 Pro。
所有模型均已发布到 Hugging Face
https://huggingface.co/collections/OpenGVLab/internvl35-68ac87bd52ebe953485927fb
该模型的技术亮点:
-
Cascade Reinforcement Learning(Cascade RL):采用“离线 RL + 在线 RL”两阶段策略,实现更加稳健收敛和精细对齐,从而显著增强模型的推理能力,在 MMMU 和 MathVista 等任务上表现提升明显。
-
Visual Resolution Router(ViR):动态调整视觉 token 的分辨率,兼顾性能与效率,使视觉理解更加灵活高效。
-
Decoupled Vision-Language Deployment(DvD):将视觉编码器与语言模型分开部署至不同 GPU,有效平衡资源负载,提升推理速度。
在推理性能提升高达 16.0%(整体推理任务中),同时相较于 InternVL3,实现了 4.05× 的推理速度加速。