RWKV 创始人彭博刚刚在社交平台发布了一篇文章,主要讨论 DeltaNet 和 RWKV-7 在基线测试中的问题。
来源:
- https://zhuanlan.zhihu.com/p/1915054612559426430
- https://github.com/BlinkDL/zoology
事件主角 DeltaNet 和 RWKV 均为中国团队创建的 LLM 架构:
DeltaNet 是结合线性 Transformer 和非线性 Transformer 架构的模型,通过特定方法将非线性 Transformer 转换为线性 DeltaNet 形式,从而在保持性能的同时提高计算效率,经实验验证,在特定数据集上能取得与原始非线性模型相当的性能。
https://sustcsonglin.github.io/blog/2024/deltanet-1/
RWKV(是一种具有 GPT 级大型语言模型(LLM)性能的 RNN,也可以像 GPT Transformer 一样直接训练(可并行化)。 RWKV 结合了 RNN 和 Transformer 的最佳特性:出色的性能、恒定的显存占用、恒定的推理生成速度、"无限" ctxlen 和免费的句嵌入,而且 100% 不含自注意力机制。
https://rwkv.cn/docs/RWKV-Wiki/Introduction
RWKV 创始人发布的文章篇幅较长,核心内容如下:
一、从社交平台开始的争议
-
事件起源:
-
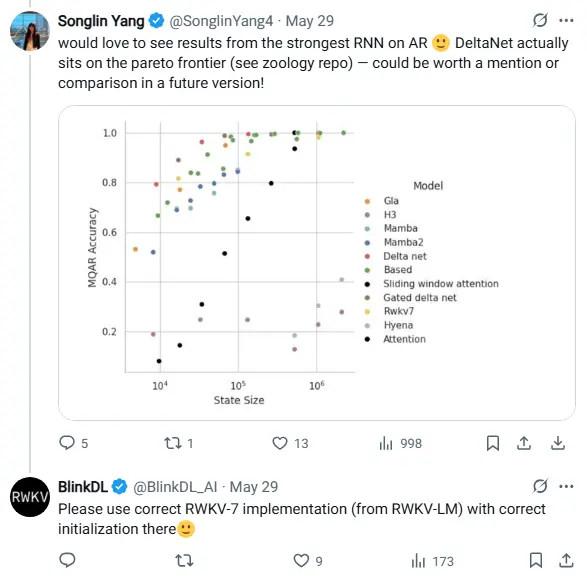
DeltaNet 作者 Songlin 在 X 平台发文,其中提到 RWKV-7 数据与论文中的结果有显著差异。
-
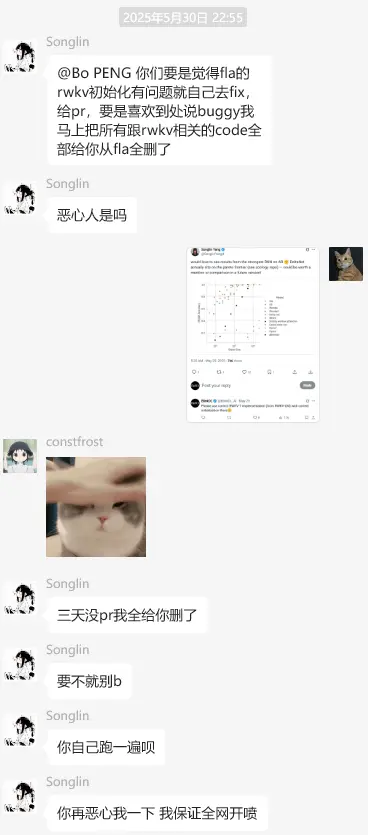
RWKV 创始人指出错误后(对方在测试 RWKV-7 时使用了非官方实现的代码库,导致结果严重偏差),DeltaNet 团队在微信群以激烈言辞回应(如群内置顶“恶言”),引发争议。
-
RWKV 创始人在查看对方用于测试模型架构的项目代码后(HazyResearch/zoology),发现了两大问题:
-
State Size 计算错误:
RWKV-7 的 state size 被错误公式num_heads * k_dim * v_dim计算(正确应为num_heads * head_k_dim * head_v_dim),导致参数膨胀数倍(如 d_model=256 时膨胀 16 倍)。 -
ShortConv 应用不一致:
zoology 为所有架构添加了shortconv length=4以提升 MQAR 任务性能,但唯独未给 RWKV-7 添加,使其处于不公平劣势。
二、技术验证:RWKV-7 的数学优越性
-
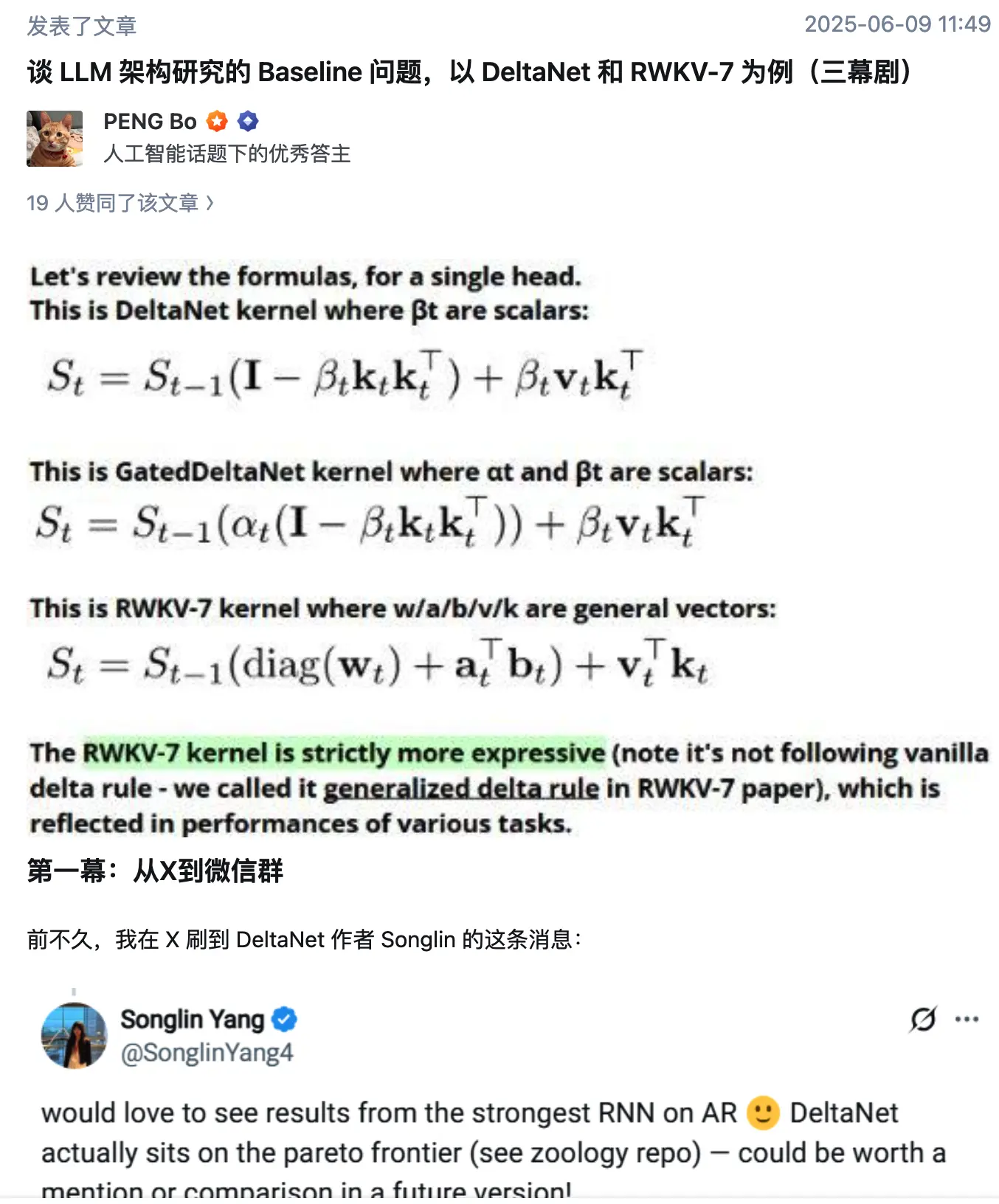
算子表达力对比:
-
DeltaNet/GatedDeltaNet:使用标量参数(βt 或 αt, βt),表达力有限。
-
RWKV-7:使用矢量参数(w, a, b, v, k),数学上严格包含 DeltaNet 等架构(例如可通过参数设定退化为 BetterDeltaNet)。
-
-
实验证明:
-
将 DeltaNet 内核替换为 RWKV-7 内核(BetterDeltaNet),在相同 MQAR 任务(8192 state size, 256 kv pairs)中准确率提升:
14.31% → 13.09%(RWKV-7 胜出)。 -
证明 RWKV-7 的优越性源于其数学形式,而非 "trick"。
-
总的来说,RWKV-7 的核心算子在数学上更通用,表达力更强,因此在性能上具有优势。同时,作者批评了 Zoology 库在测试中对 RWKV-7 的不公平对待。
三、对学术圈的批判与反思
-
刻意压低 Baseline 的现象:
-
指出许多论文存在 "deliberate carelessness"(有意的无意),通过不公平测试贬低他人工作(如 RWKV 系列长期被恶意对比)。
-
强调合理基线需满足:
(1) 使用原作者提供的实现细节;
(2) 公平应用关键改进(如 shortconv)。
-
-
RWKV-7 的实践验证:
-
模型规模:RWKV7-G1(2.9B/1.5B)是训练 token 最多的纯 RNN 架构模型(10+ T tokens)。
-
数据压缩能力:在未知数据(2025年4月)的字节压缩测试中表现优异(见 UncheatableEval)。
-
更多细节和数据查看:
- https://zhuanlan.zhihu.com/p/1915054612559426430
- https://github.com/BlinkDL/zoology