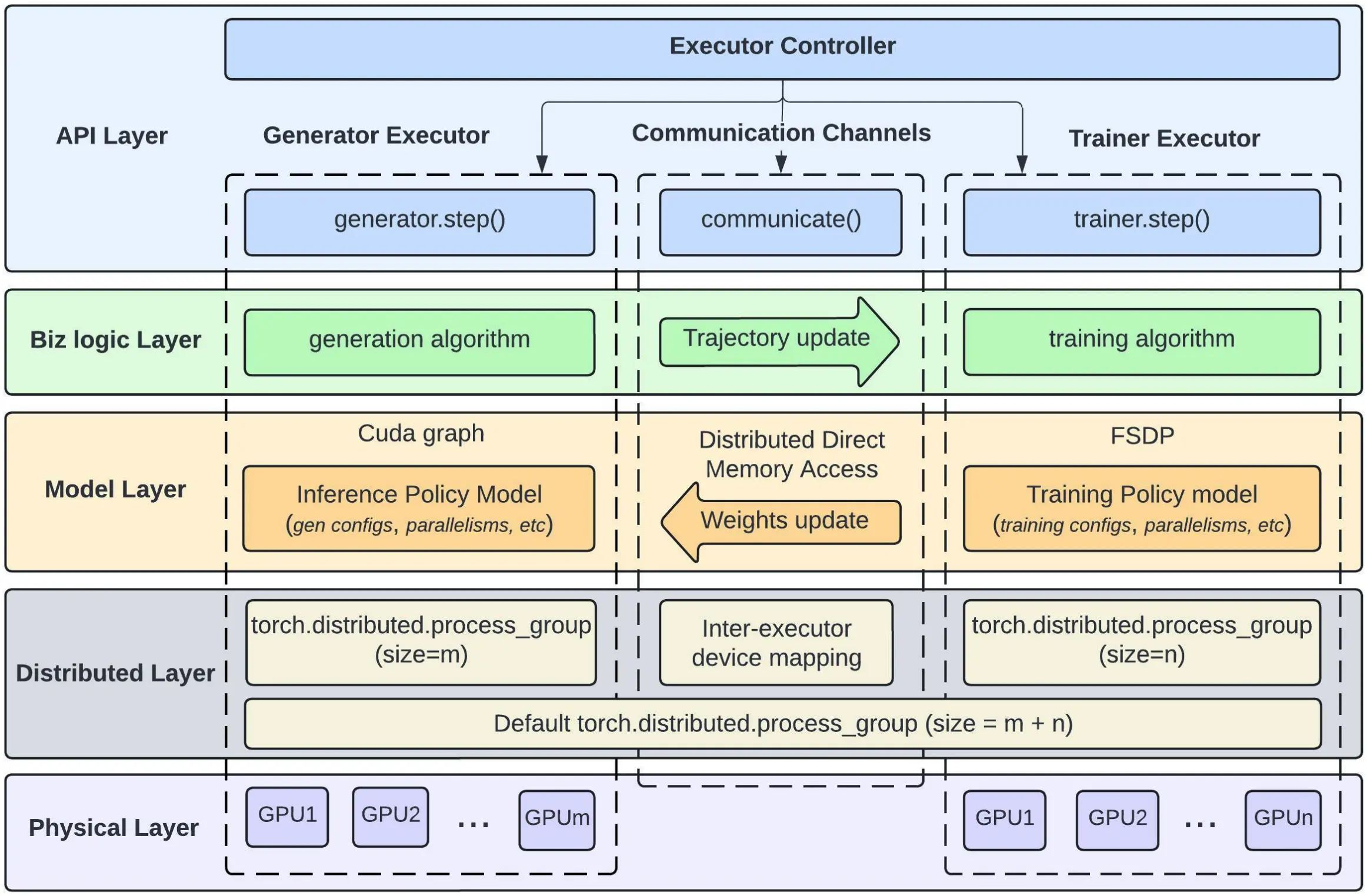
Meta 发布了 LlamaRL 强化学习框架,基于 PyTorch 构建全异步分布式架构,通过独立执行器并行处理生成、训练和评分任务,并整合 DDMA 和 NVLink 技术实现高效数据传输。
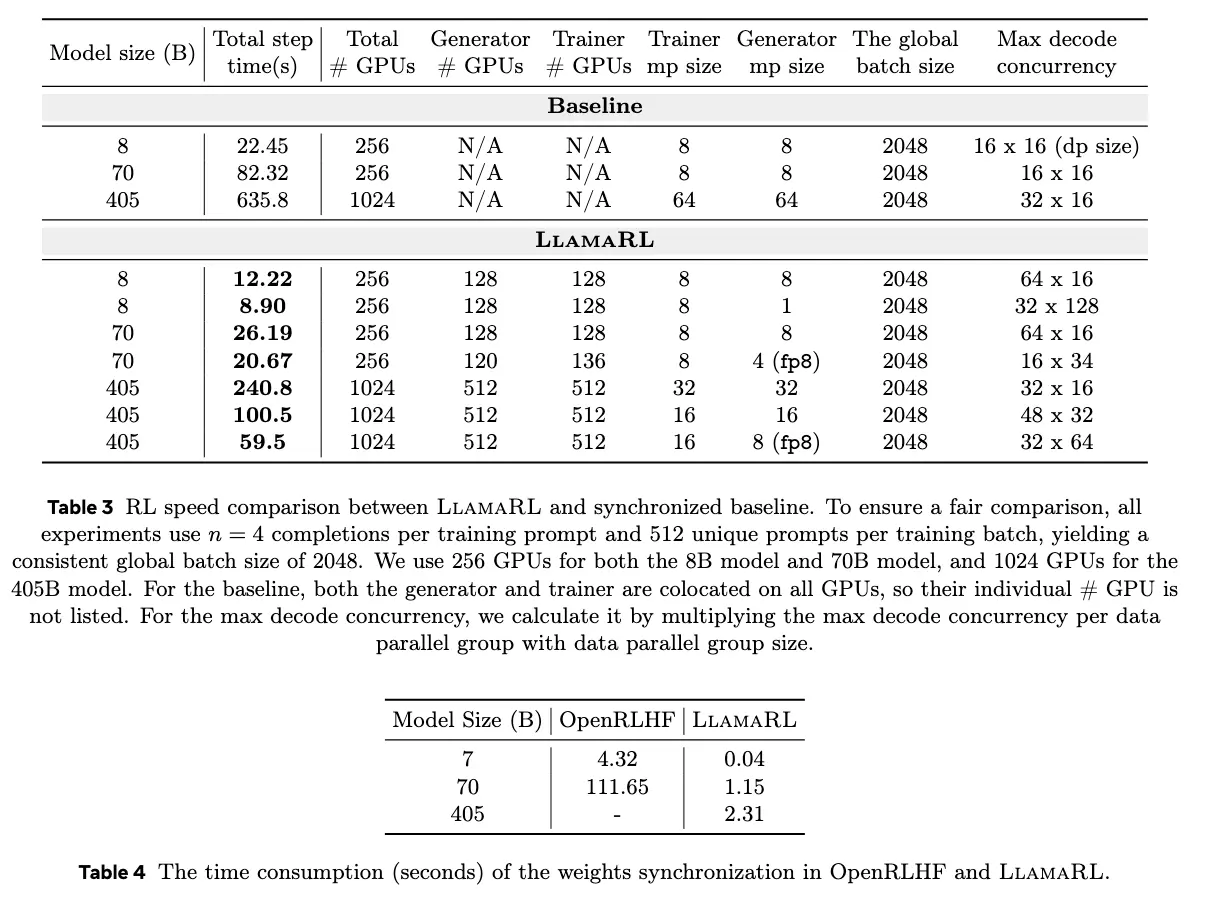
实测显示,该框架在 4050 亿参数模型中,将强化学习步骤耗时从 635.8 秒缩减至 59.5 秒,效率提升 10.7 倍,80 亿、700 亿参数模型训练时间分别缩短至 8.90 秒、20.67 秒。其突破内存瓶颈与 GPU 利用率难题,同时在 MATH 和 GSM8K 等标准测试中模型表现稳定甚至增强,为未来更大规模模型训练提供可扩展解决方案。
论文地址:https://arxiv.org/abs/2505.24034