Helix 是一个模态文本编辑器,内置支持多选、语言服务器协议 (LSP)、tree-sitter 以及对调试适配器协议 (DAP) 的实验性支持。目前 Helix 22.12 版本已发布,这是一个功能丰富的版本,带来如下内容:
Git diff gutter
新的 git diff gutter 跟踪当前缓冲区中与 git 索引相比的变化。 与签入到 git 的文件相比,装订线中的标记表示添加、修改和删除。
默认情况下启用 git diff gutter。
下划线样式和颜色
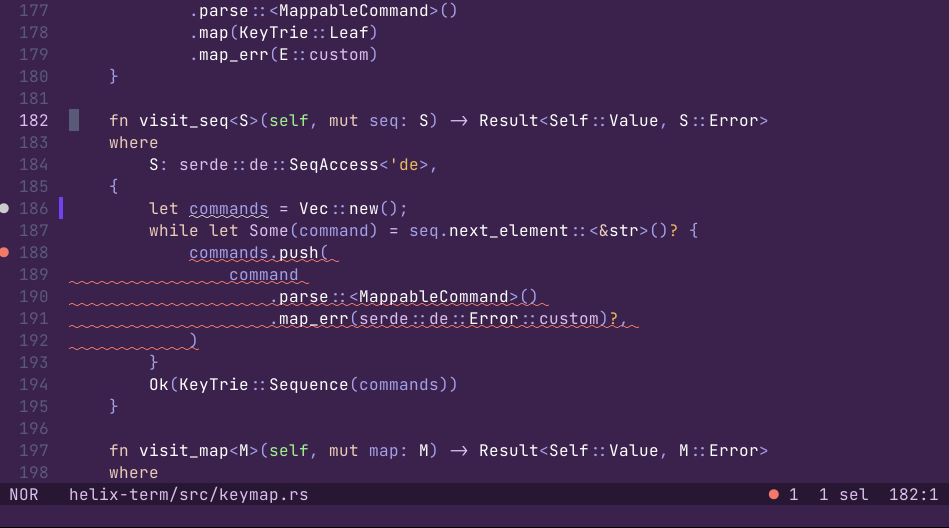
支持扩展下划线的终端可以呈现彩色波浪线或点等样式的下划线,扩展的下划线可用于改进 LSP 诊断的显示。
终端失去焦点时自动保存
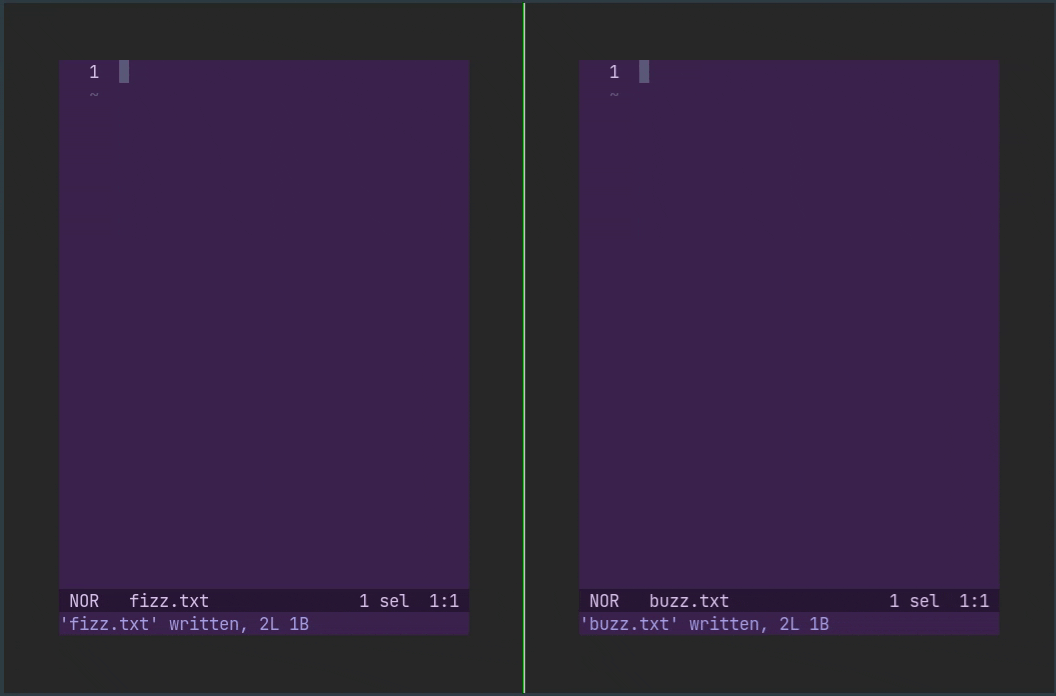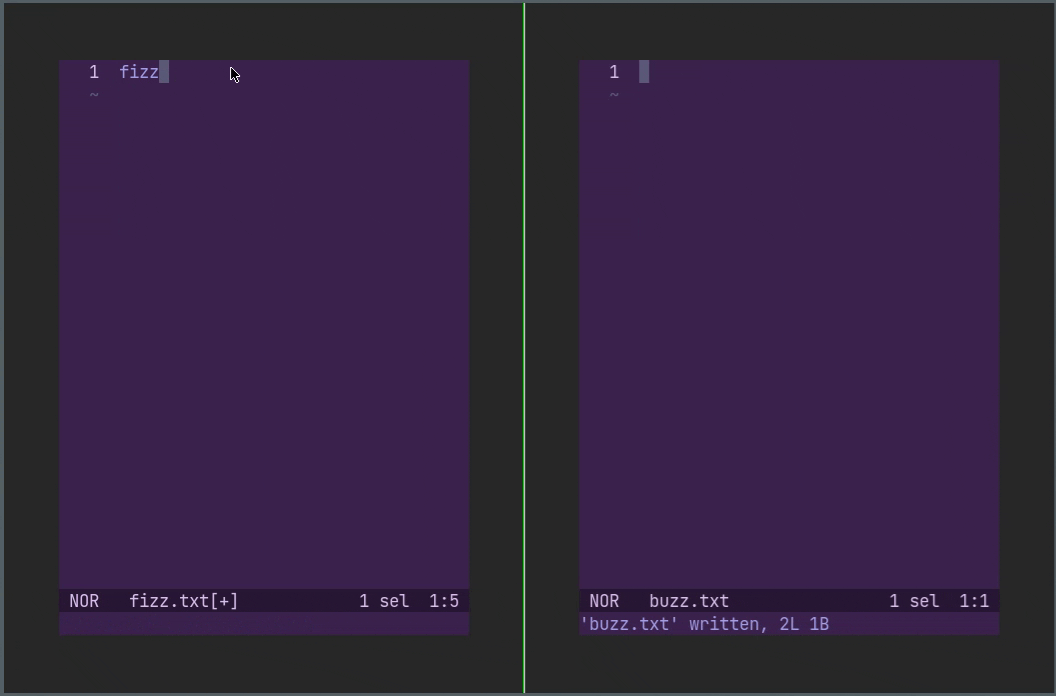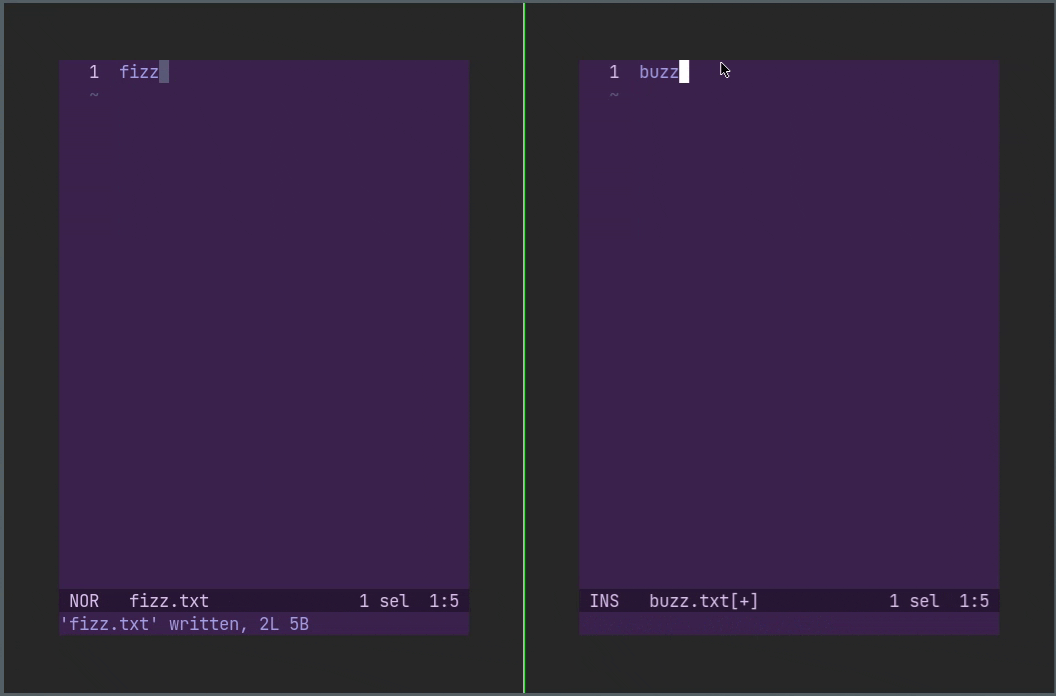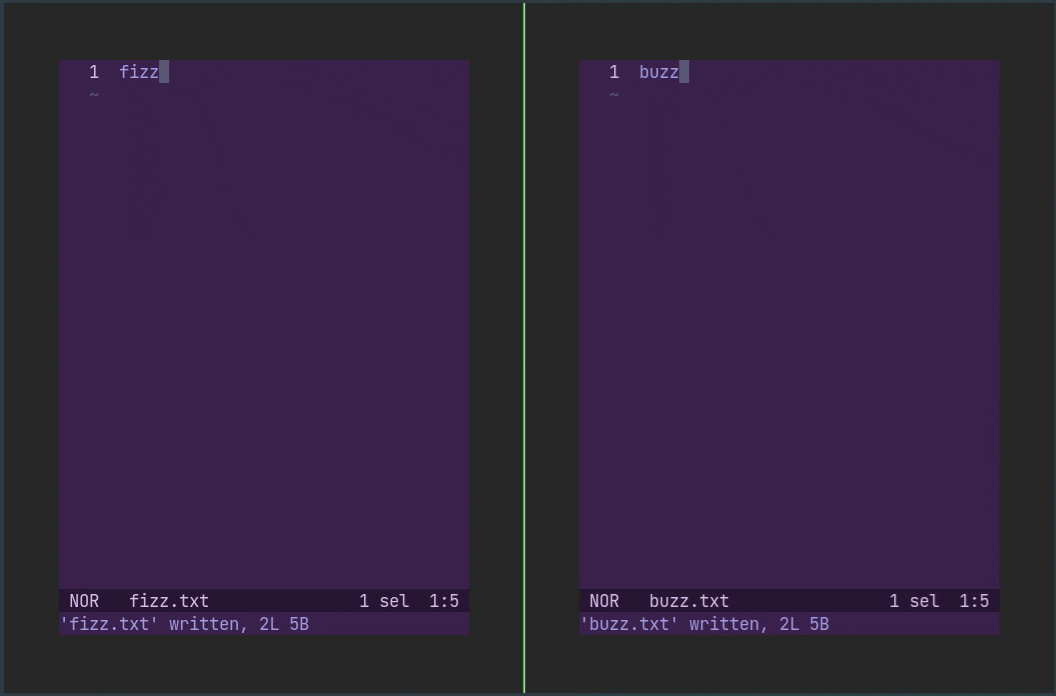
支持焦点事件的终端可以在切换到新窗口时自动保存当前文件。
幕后的性能改进:
- 用于写入文件的代码路径已经过全面检查,修复了一些围绕写入大文件和写入失败的边缘情况。
- tree-sitter 解析、查询和注入处理的性能得到了改进,这对于大型 Markdown 文件来说是一个明显的速度提升,特别是因为 Markdown 广泛使用注入。
- LSP 代码路径中的故障处理已得到改进, Helix 现在可以优雅地处理语言服务器不支持功能和语言服务器意外崩溃等情况。
- :reload 命令的速度和内存使用得到了极大的改进,该改进来自 imara-diff 的创建,这是一种新的 diffing 实现,比 git 内部使用的更快。
更新公告:https://helix-editor.com/news/release-22-12-highlights/